前端性能优化
- 优先优化对性能影响大的部分
- 对高频触发的事件进行节流或消抖
- JavaScript 很快,DOM 很慢
- 优化渲染性能
- 优化 JavaScript 的执行
- 优化 CSS
- 合理处理脚本和样式表
- 参考资料
- GPU 是如何加速网页渲染的
最近工作中一个项目在运行时有一些性能问题,为此我看了很多与性能优化相关的内容,下面做个简单的分享。
前端性能优化,这包括 CSS/JS 性能优化、网络性能优化等等内容,这方面的内容 《高性能网站建设指南》、《高性能网站建设进阶指南》、《高性能JavaScript》 等等书都做了很多讲解,强烈推荐阅读。
下面的内容,上面提到的书中大都包含了,因此可以考虑转而去读这些书,做一个完完全全的了解,对于本文,也就不要再读下去了。
如果你坚持看到了这里,那就来谈谈我遇到的一些前端性能问题,并聊聊解决方案。
优先优化对性能影响大的部分
当应用有了性能问题后,不要一股脑扎到代码中去,首先要想想那部分对性能影响最大。优先优化那些对性能影响大的部分,可以起到立杆见影的效果。 使用 Chrome DevTools ,可以很快地找到导致性能变差的最主要因素,关于 Chrome DevTools 的使用强烈推荐阅读 Google Developers 上面的系列教程 - Chrome DevTools。
另外在对代码进行优化的时候,也首先要关注那些存在循环或者高频调用的地方。有的时候我们可能不知道某个地方是否会高频执行,比如某些事件的回调。这个时候可以使用 console.count 来对执行次数进行统计。当这部分高频执行的代码已经足够优化的时候,就要考虑是否能够减少执行次数。比如一个时间复杂度为 O(n*n*n) 的算法,再怎么优化也不如将其变为 O(n*n) 来的快。
对高频触发的事件进行节流或消抖
对于 Scroll 和 Touchmove 这类事件,永远不要低估了它们的执行频率,处理这类事件的时候可以考虑是否要给它们添加一个节流或者消抖过的回调。节流和消抖,可能其他人不这么翻译,其实也就是 debounce 和 throttle 这两个函数。
debounce 和 throttle 是两个相似(但不相同)的用于控制函数在某段事件内的执行频率的技术。你可以在 underscore 或者 lodash 中找到这两个函数。
使用 debounce 进行消抖
多次连续的调用,最终实际上只会调用一次。想象自己在电梯里面,门将要关上,这个时候另外一个人来了,取消了关门的操作,过了一会儿门又要关上,又来了一个人,再次取消了关门的操作。电梯会一直延迟关门的操作,直到某段时间里没人再来。
所以 debounce 适合用在比如对用户输入内容进行校验的这种场景下,多次触发只需要响应最后一次触发就好了。
使用 throttle 进行节流
将频繁调用的函数限定在一个给定的调用频率内。它保证某个函数频率再高,也只能在给定的事件内调用一次。比如在滚动的时候要检查当前滚动的位置,来显示或隐藏回到顶部按钮,这个时候可以使用 throttle 来将滚动回调函数限定在每 300ms 执行一次。
需要提到的是,这两个函数常常被误用,且很多时候当事人并没有意识到自己误用了。我曾经用错过,也见过别人用错。这两个函数都接受一个函数作为参数,然后返回一个节流/去抖后的函数,下面第二种用法才是正确的用法:
// 错误的用法,每次事件触发都得到一个新的函数
$(window).on('scroll', function() {
_.throttle(doSomething, 300);
});
// 正确的用法,将节流后的函数作为回调
$(window).on('scroll', _.throttle(doSomething, 200));
JavaScript 很快,DOM 很慢
JavaScript 如今已经很快了,真正慢的是 DOM。因此避免使用一些不易读但据说能提高速度的写法。不久前,一位朋友对我说使用 ‘+’ 号将字符串转为数字比使用 parseInt 快。对此我并没有怀疑,因为直觉上 parseInt 进行了函数调用,很可能会慢一些,我们一起在 在 node v6.3.0 上进行了一些验证,结果的确如我们所预计的那样,但是差别有多大呢,进行了 5 亿次迭代,使用 ‘+’ 号的方法仅仅快了2秒。但实际中将字符转为数字的操作可能只会进行几次,这种写法只会导致代码质量降低。
plus: 1694.392ms
parseInt: 3661.403ms
真正慢的是 DOM,DOM 对外提供了 API,而 JavaScript 可以调用这些 API,它们两者就像是使用一座桥梁相连,每次过桥都要被收取大量费用,因此应该尽量让减少过桥的次数。
为什么 DOM 很慢
谈到这里需要对浏览器利用 HTML/CSS/JavaScript 等资源呈现出精彩的页面的过程进行简单说明。浏览器在收到 HTML 文档之后会对文档进行解析开始构建 DOM (Document Object Model) 树,进而在文档中发现样式表,开始解析 CSS 来构建 CSSOM(CSS Object Model)树,这两者都构建完成后,开始构建渲染树。整个过程如下:
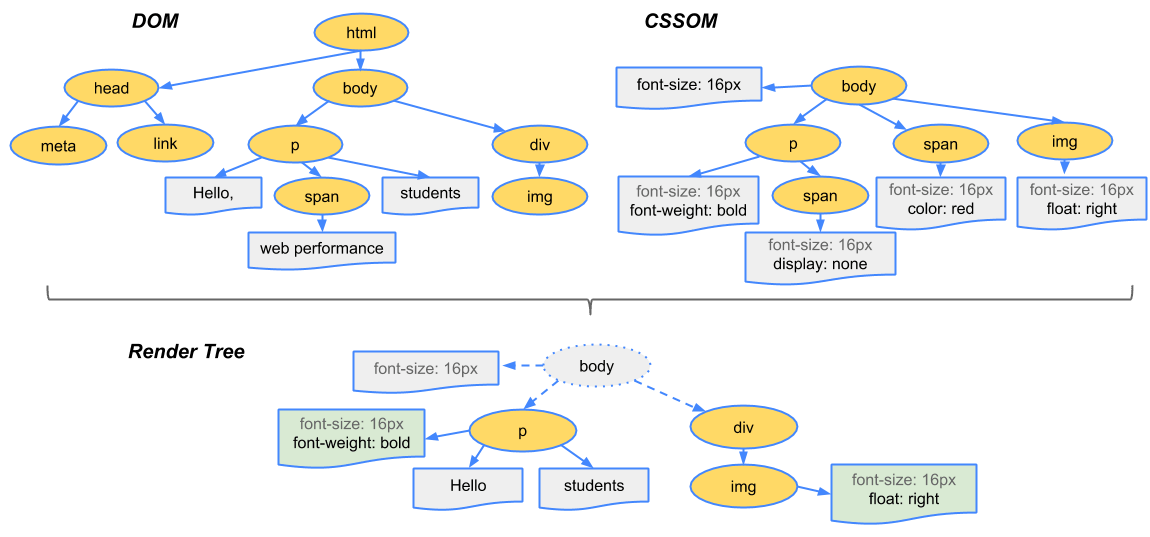
在每次修改了 DOM 或者其样式之后都要进行 DOM树的构建,CSSOM 的重新计算,进而得到新的渲染树。浏览器会利用新的渲染树对页面进行重排和重绘,以及图层的合并。通常浏览器会批量进行重排和重绘,以提高性能。但当我们试图通过 JavaScript 获取某个节点的尺寸信息的时候,为了获得当前真实的信息,浏览器会立刻进行一次重排。
避免强制性同步布局
在 JavaScript 中读取到的布局信息都是上一帧的信息,如果在 JavaScript 中修改了页面的布局,比如给某个元素添加了一个类,然后再读取布局信息。这个时候为了获得真实的布局信息,浏览器需要强制性对页面进行布局。因此应该避免这样做。
批量操作 DOM
在必须要进行频繁的 DOM 操作时,可以使用 fastdom 这样的工具,它的思路是将对页面的读取和改写放进队列,在页面重绘的时候批量执行,先进行读取后改写。因为如果将读取与改写交织在一起可能引起多次页面的重排。而利用 fastdom 就可以避免这样的情况发生。
虽然有了 fastdom 这样的工具,但有的时候还是不能从根本上解决问题,比如我最近遇到的一个情况,与页面简单的一次交互(轻轻滚动页面)就执行了几千次 DOM 操作,这个时候核心要解决的是减少 DOM 操作的次数。这个时候就要从代码层面考虑,看看是否有不必要的读取。
另外一些关于高效操作 DOM 的方法,可以参见《高性能 JavaScript》相关章节,也可以先参考一下我的读书笔记 《高性能 JavaScript》
优化渲染性能
浏览器通常每秒更新页面 60 次,每一帧的时间就是 16.6ms,为了能让浏览器保持 60帧 的帧率,为了让动画看起来流畅,需要保证帧率达到 60fps,因此每一帧的逻辑需要在 16.6ms 内完成。
每一帧实际上都包含下列步骤:

因此,通常 JavaScript 的执行时间不能超过 10ms。
- JavaScript:改变元素样式,添加元素到 DOM 中等等
- Style:元素的类或者style改变了,这个时候需要重新计算元素的样式
- Layout:需要重新计算元素的具体尺寸
- Paint:将元素的绘制的图层上
- Composite:合并多个图层
当然也不是说每一帧都会进行这些操作。当你的 JavaScript 改变了某个 layout 属性,比如元素的 width 和 height 或者 top 等等,浏览器就会重新计算布局,并对整个页面进行重排。
如果修改了 background、color 这样的仅仅会让页面重绘的属性,这不会影响页面的布局,浏览器会跳过计算布局(layout)的过程,只进行重绘(paint)。
如果修改了一个不需要计算布局也不需要重绘的属性,那就只会进行图层的合并,这是代价最小的修改。从 https://csstriggers.com/ 上你可以知道修改那些样式属性会触发(Layout,Paint,Composite)中的那些操作。
将渐变或者会动画元素放到单独的绘制层中
绘制并非在一个单独的画布上进行的,而是多层。因此将那些会变动的元素提升至单独的图层,可以让他的改变影响到的元素更少。
可以使用 CSS 中的 will-change: transform; 或者 transform: translateZ(0); 这样来将元素提升至单独的图层中。
在调试的时候你可以在 Chrome DevTools 的 timeline 面板来观察绘制图层。当然也不是说图层越多越好,因为新增加一个图层可能会耗费额外的内存。且新增加一个图层的目的是为了避免某个元素的变动影响其他元素。
降低绘制复杂度
某些属性的重绘相对而言更加复杂,比如 filter、box-shadow 等滤镜或渐变效果。因此不要滥用这类效果。
优化 JavaScript 的执行
下面提到的 JavaScript 优化,并不是说如何让 JavaScript 执行的更快,而是如何让 JavaScript 更高效地与 DOM 配合。
使用 requestAnimationFrame 来更新页面
我们希望在每一帧刚开始的时候对页面进行更改,目前只有使用 requestAnimationFrame 能够保证这一点。使用 setTimeout 或者 setInterval 来触发更新页面的函数,该函数可能在一帧的中间或者结束的时间点上调用,进而导致该帧后面需要进行的事情没有完成,引发丢帧。
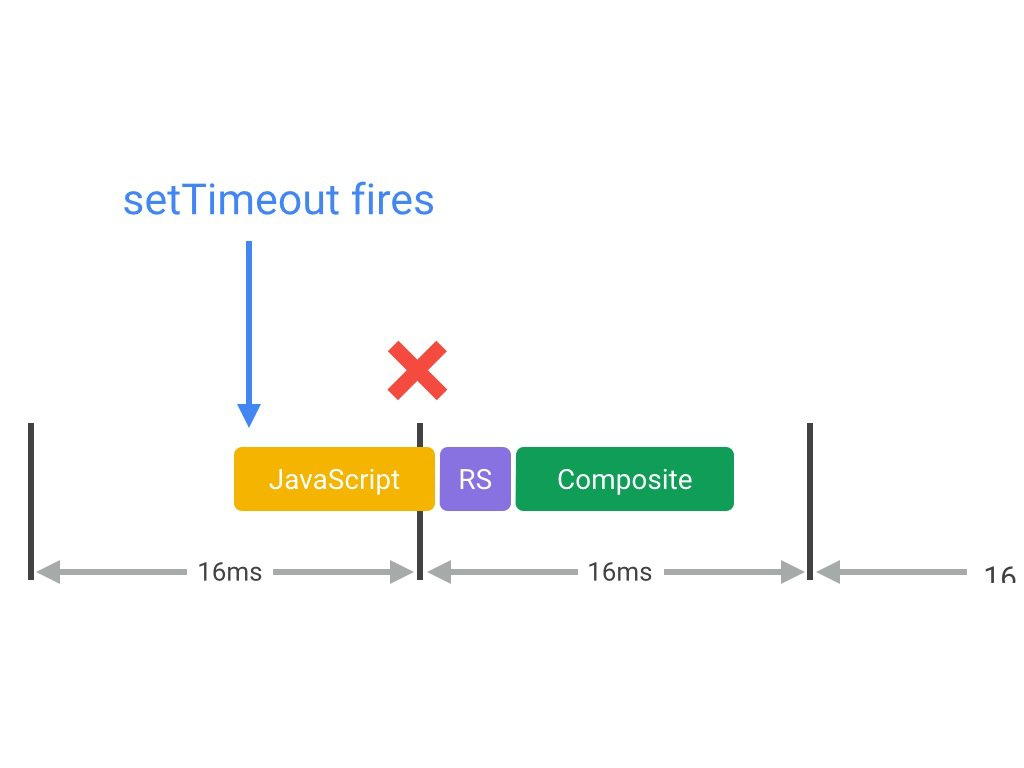
requestAnimationFrame 会将任务安排在页面重绘之前,这保证动画能有足够的时间来执行 JavaScript 。
使用 Web Worker 来处理复杂的计算
JavaScript 是在单线程的,并且可能会一直这样,因此 JavaScript 在执行复杂计算的时候很可能会阻塞线程,导致页面假死。但 Web Worker 的出现,以另外一种方式给了我们多线程的能力,可以将复杂计算放在 worker 中进行,当计算完成后,以 postMessage 的形式将结果传回来。
对于单个函数,因为 Web Worker 接受一个脚本的 url 作为参数,使用 URL.createObjectURL 方法,我们可以将一个函数的内容转换为 url,利用它创建一个 worker。
var workerContent = `
self.onmessage = function(evt){
// ...
// 在这里进行复杂计算
var result = complexFunc();
// 将结果传回
self.postMessage(result);
};`
// 得到 url
var blob = new Blob([workerContent]);
var url = window.URL.createObjectURL(blob);
// 创建 worker
var worker = new Worker(url);
使用 transform 和 opacity 来完成动画
如今只有对这两个属性的修改不需要经历 layout 和 paint 过程。
避免在 scroll 或 touchmove 这类事件的回调中修改样式
如果在事件监听函数中进行了 DOM 操作,这可能会消耗不少时间,事件监听函数执行的时间变长,与 GPU 进行通信的合成线程也就迟迟接收不到通知,浏览器也就迟迟不知道如何滚动页面,由此引发的就是卡顿。对于这类同步的事件(浏览器等待事件执行完成),可以在事件触发的时候先读取需要获取的 DOM 元素的尺寸位置等信息,然后将其他改写 DOM 的操作安排在 requestAnimationFrame 中完成,浏览器能够更快地执行完事件回调,还能避免后续的读取 DOM 的时候发生重排。
另外,有时候希望事件在每一帧执行一次,此时是使用 throttle 是无法满足需求的,使用 requestAnimationFrame 可以保证每一帧都会调用,需要注意的是有的事件触发的频率可能是一帧好几次。因此在使用 requestAnimationFrame 的时候要注意判断是否在一帧内多次触发了回调。
let padding = false;
function onTouchmove (evt) {
if (padding){
return;
}
padding = true;
requestAnimationFrame(function(){
// ...
padding = false;
});
}
document.body.addEventListener('touchmove', onTouchmove);
更多关于使用 requestAnimationFrame 来提升性能的细节可以阅读这篇文章:Better Performance With requestAnimationFrame
优化 CSS
CSS 选择器在匹配的时候是由右至左进行的,因此最后一个选择器常被称为关键选择器,因为最后一个选择越特殊,需要进行匹配的次数越少。要千万避免使用 *(通用选择器)作为关键选择器。因为它能匹配到所有元素,进而倒数第二个选择器还会和所有元素进行一次匹配。这导致效率很低下。
/* 不要这样做 */
div p * {}
另外 first-child 这类伪类选择器也不够特殊,也要避免将它们作为关键选择器。关键选择器越特殊,浏览器就能用较少的匹配次数找到待匹配元素,选择器性能也就越好。
还有一个老生常谈的注意事项,不要使用太多的选择器。如果还有同学很悲剧地要兼容低版本 IE,要避免使用 CSS 表达式,它的性能很差,详细内容可参见我之前记录的一篇笔记 《高性能网站建设指南》笔记
合理处理脚本和样式表
如今有了 requirejs,webpack 等工具,可能很少会在页面中加载很多 JavaScript/CSS 代码了。尽管如此,还是有必要谈谈如何合理处理脚本和样式表。
大多数人已经知道通常要把 JavaScript 放在文档底部,把 CSS 放在文档顶部。为什么呢?因为 JavaScript 会阻塞页面的解析,而外部样式表会阻塞页面的呈现和 JavaScript 的执行。
CSS阻塞渲染
通常情况下 CSS 被认为是阻塞渲染的资源,在CSSOM 构建完成之前,页面不会被渲染,放在顶部让样式表能够尽早开始加载。但如果把引入样式表的 link 放在文档底部,页面虽然能立刻呈现出来,但是页面加载出来的时候会是没有样式的,是混乱的。当后来样式表加载进来后,页面会立即进行重绘,这也就是通常所说的闪烁了。
JavaScript 阻塞文档解析
当在 HTML 文档中遇到 script 标签后控制权将交给 JavaScript,在 JavaScript 下载并执行完成之前,都不会解析 HTML。因此如果将 JavaScript 放在文档顶部,恰好这个时候 JavaScript 脚本加载的特别慢,用户将会等待很长一段时间,这段个时候 HTML 文档还没有解析到 body 部分,页面会是空白的。
另外常常被忽略的事实是:在浏览器没有下载并解析完成使用 link 引入的 CSS 文件之前,JavaScript 是不会执行的,因为 JavaScript 中可能需要读取样式,而此时样式表还没有加载回来,因此浏览器不会执行 JavaScript。可以给 JavaScript 加上 async 标记,表示 JavaScript 的执行不会读取 DOM ,JavaScript 可以不被 CSS 阻塞,可以在空闲时间立刻执行。
综上所述,你更要保证 CSS 文件加载的足够快。
关于这部分内容, 《高性能网站建设指南》 上有很精彩的讲解,墙裂推荐。《高性能网站建设指南》我在读的时候记录了笔记,可以在这里看到。
最后强烈推荐阅读 Google Developers 中关于性能优化的系列文章。
参考资料
- 《高性能网站建设指南》
- 《高性能网站建设进阶指南》
- 《高性能JavaScript》
- Google Developers
- Efficient JavaScript
- Best Practices for Speeding Up Your Web Site
前端性能优化
GPU 是如何加速网页渲染的
上次修改时间: 2016-11-01
前端工程师应该都听说过硬件加速,通常它是指利用 GPU 来加速页面的渲染。那么 GPU 目前在web页面的渲染过程中起到什么作用呢?
GPU 的作用
早期浏览器完全依赖 CPU 来进行页面渲染。现在随着 GPU 的能力增强和普及,且目前绝大多数运行浏览器的设备上都集成了 GPU。浏览器可以利用 GPU 来加速网页渲染。
GPU 包含几百上千个核心,但每个核心的结构都相对简单, GPU 的结构也决定了它适合用来进行大规模并行计算。进行图层合并需要操作大量的像素,这方面 GPU 能比 CPU 更高效的完成。这里有个视频,很清楚地说明 CPU 与 GPU 的差别。
页面渲染过程
浏览器利用 HTML 构建出 DOM 树,利用 CSS 构建 CSSOM 树,最终得到 Render 树。
然而这只是很宏观的描述,浏览器为了将 DOM 元素高效地绘制且正确地出来,将多个元素安排在一个图层中,使用 PaintLayer 来描述,在每个 PaintLayer 中又存在 GraphicsLayers。当某个元素的样式改变后,不需要去重绘某个图层就好了。
浏览器的每一帧都可能会经过以下几个步骤:
JavaScript 的执行可能修改 DOM 树和 CSSOM 树,随后浏览器需要重新计算样式,并根据新的样式计算出元素的实际属性(比如 CSS 中 width 是 50%,这里就要利用父元素的宽度得出自己真实的 width 值),重绘有变动的图层,随后将各图层传递给 GPU ,由 GPU 来进行图层的合并。
上面 5 个步骤中,Layout 和 Paint 是可以省略的,当修改后的样式不会改变元素的尺寸、位置等涉及布局的属性时候,就没有必要进行 Layout(计算布局),比如修改了 color 属性,这个时候就只需要进行重绘(Paint)步骤。同样的道理,修改某些属性也不需要进行 Paint 步骤,只需要 Composite 就可以。
因此,我们希望所做的操作能尽可能地避免 Layout 和 Paint 这两个步骤,这样一帧所需的时间也就会大大缩短,可以明显避免卡顿。
目前有三个属性的改变只需要进行 Composite 过程,分别是:
- filter
- transform
- opacity
这几个属性的改变,GPU 只需要在合并图层之前对图层进行一些变换,比如 opacity 属性的改变,GPU 只需要在合并之前改变图层的 alpha 通道。transform 和 filter 的改变 GPU 也可以很快地得到相应的图层。
正确地利用 GPU
使用 transform, filter 和 opacity 来完成动画
使用以上 3 个属性来完成动画,可以避免在动画的每一帧进行重绘。如果在动画中改变了其他属性,那也不能避免重新绘制。
避免不合理地强制开启硬件加速
常常看到有文章指出使用 transform:translateZ(0); 这样的 hark 可以强制开启硬件加速来提高性能,这是错误的说法,要知道所谓的硬件加速就是利用 GPU 来将本就存在于 GPU 中的图层进行一些变换得到新的图层。如果改变的属性必须要要进行重绘,比如改变了 background 属性,那么图层还是要进行重绘然后重新加载至 GPU 中。这个时候就算强制开启硬件加速也没有什么用。
使用 transform:translateZ(0); 这样的 CSS hark 写法会将元素提升至单独的图层。在这么做之前要考虑为什么要这样做,创建新的图层的目的应该是,避免某个元素的改变导致大面积重绘,比如某个小标签的颜色的改变,导致大面积重绘,因此将其提升至单独的图层中。这里有个例子,小标签背景色的改变会导致大面积的重绘,但是如果将其提升至单独的图层后,改变它的背景色将只会重绘它自身。你可以代码 Chrome 调试工具,通过 Timeline 观察每次闪烁重绘的内容。
而如果整个图层的都要被重绘,那么再将其中的部分元素提升至单独的图层,会导致重绘的时候会分多个图层来进行绘制,然后在进行多个图层的合并,这个时候不如将所有元素放置在单个图层中,重绘整个大的图层。
总结
所谓硬件加速,早起浏览器是使用纯软件来渲染页面的,如今现代浏览器利用了 GPU 来进行页面的渲染,在合适的时候浏览器就会自动去使用 GPU 而不是开发者自己去指定。GPU 的功能是在合并图层阶段,它可以在进行图层合并之前来对原图层进行一些变换,合理地使用这个变换可以避免页面重绘,使得每一帧消耗的时间最少,避免卡顿。