关于 TCP 协议
TCP 首部
下图中为 TCP 首部的布局:

-
源端和目的端端口:与 IP 首部的源 IP 和目的 IP 构成四元组,这个四元组唯一确定一对连接双方。在网络编程中,这个四元组对应一个已经连接的 socket。
-
序号:用来标识当前报文,因为 TCP 分组可能乱序到达对端,对端需要根据序号重新整理数据。起始序号并非为 0,而是由网络软件经过某种策略得出的。
-
确认序号:用来告知对方当前已经成功接收的数据的序号。比如确认序号为 3,说明 3 之前的字节全部收到了。当前期望接收编号为 3 的字节。
-
首部长度指出首部中包含的 32bit 的数量,即有多少个 4 字节,另外首部长度占 4bit,最大可以表示的数为 15,因此,因此 TCP 首部最大长度为 60 字节。在没有选项字段的时候,TCP 首部长度为 20 字节。
- 标志位:标志位可为 0 或 1,为 1 时表示开启。
- URG:urgent,表示当前数据中包含紧急数据,紧急指针指向紧急数据的最后一个字节。
- ACK:acknowledge,和确认序号配合用来确认对方发来的数据。ACK 为 1 的时候,确认序号才有效。
- PSH:push,表示希望对端应用层应该尽快读取数据。
- RST:reset 如果连接出错,此标志位表示将连接复位。
- SYN:sync,同步,在建立连接时使用,详见三次握手。
- FIN:final,在断开连接时使用,详见四次挥手。
-
窗口大小:用于流量控制,窗口大小告知对方自己的接收缓冲区的大小。对方据此确定可以发送多少数据。不至于一次性发送很多数据过来。
- 检验和:发送端计算校验和,接收端验证校验和。保证数据没有在传输过程中出错。如果发现出错,就抛弃该 TCP 报文。计算方法如下:

原 TCP 首部上面加上一个伪首部,即上图中前三行红色部分。伪首部中加入了 IP 地址,TCP 的协议号,TCP 数据报长度。这是为了增加校验和的检错能力,比如 TCP 报文是否从正确的地址接收(源和目标IP地址)、传输层协议是否正确(传输层协议号)等。由于 CheckSum 事先是不知道的,因此在计算校验和的时候先把 CheckSum 置零。
- 选项:选项字段中可以包含多个可选字段,它的编码方式如下:
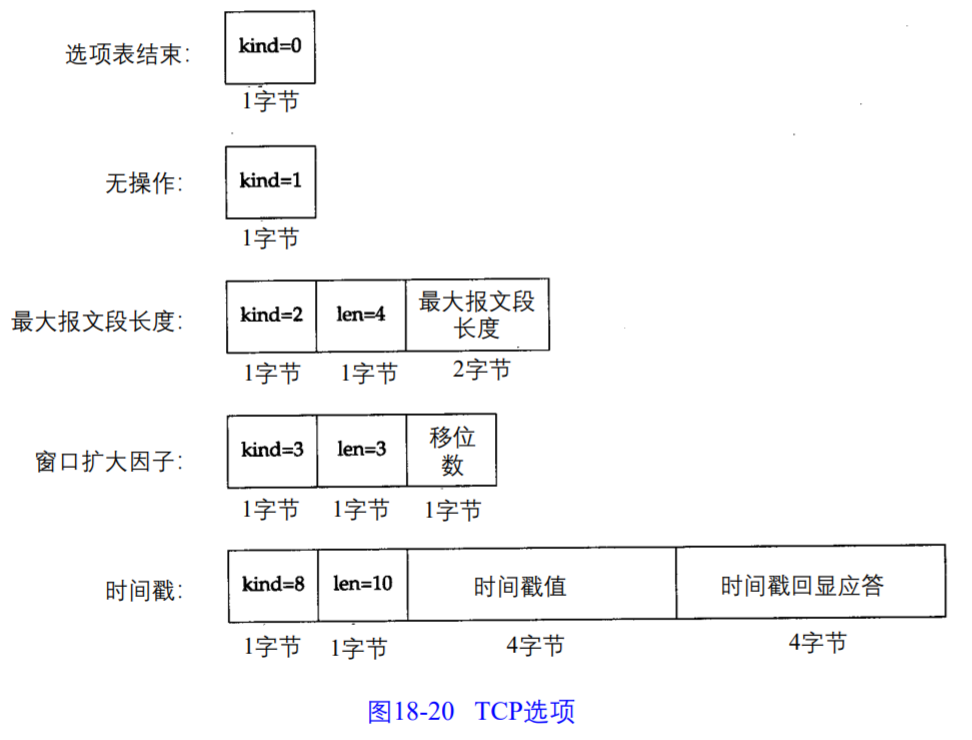
第一个字节 kind 指明选项的类别,其后为该选项信息长度,之后是该选项的值。各选项是变长的,为了保证各个选项以 4 字节对齐,“无操作”用来填充。
最常见的可选字段为最长报文大小,又称为 MSS (Maximum Segment Size)。每个连接通常在首个报文中指明这个选项。它表示本端能够接收的最长报文段。
由于 TCP 头部的窗口大小字段只有 16 位,能表示的最大值为 65535,这就限制了窗口最大为 64KB,但常常接收缓冲区比这要大很多,窗口扩大因子用来扩大窗口大小的量级,即乘上扩大因子后为真实的窗口大小。
- 数据:这部分也是可有可无的,SYN 和 FIN 报文只携带头部,不包含数据。
TCP 的连接与终止
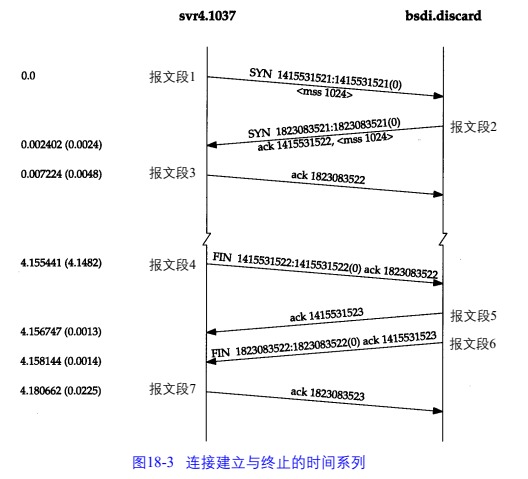
连接的建立
- 请求端发送 SYN 段表明客户打算连接的服务器端口,一级初始序号(上图中 1415531521)
- 客户端返回一个初始需要的 SYN 报文段作为应答,同时将客户的初始序号+1,作为对客户请求的应答
- 客户必须将确认需要设置为服务器的初始序号+1,作为对服务器的 SYN 段的应答。
以上三个报文段完成连接的建立,也被称为三次握手。
问题:能不能两次握手,客户端发 SYN,服务端收到后发 ACK,此时双方就可以通信了。
答案:不能,原因如下:
TCP 通信的双方都有一个自己的 sequence number,每一个 TCP 报文段都有一个 sequence number,对端根据该 sequence number,使用 ACK 来确认已经收到的报文段。
在 TCP 通信中,双方起始的 sequence number (Initial Sequence Number, ISN) 是系统生成的,通常每次 TCP 连接的 ISN 都不同。因此双方都需要告知对方自己的 ISN。
如果把三次握手分开来看:
client ----SYN---> server # 我的 ISN 是 X
client <---ACK---- server # 已收到你的 ISN,通过 ACK X+1 确认收到
client <---SYN---- server # 我的 ISN 是 Y
client ----ACK---> server # 已收到你的 ISN,通过 ACK Y+1 确认收到
第一步,客户端告知服务端自己的 ISN X。第二步,服务端确认该 ISN,为了证明自己真的收到了,使用 ACK X+1 来确认收到。同理,三和四两个步骤,服务端告知客户端自己的 ISN。
以上步骤中中间两个步骤可以合并起来,即:
client ----SYN---> server
client <-ACK/SYN-- server
client ----ACK---> server
以上就是三次握手了。但是如果是两次,那么有一端是没法确认对方收到了自己的 ISN 的。比如:
如果是:
client ----SYN---> server
client <---ACK---- server
此时客户端根本不知道服务端的 ISN。有人会说,TCP 报文头部不是有 32 位序号吗,在服务端对 SYN 发送 ACK 时,使用该报文的序号作为服务端的 ISN 不就好了。这是不行的,考虑如下场景:
客户端发送 SYN 并携带 ISN X 给服务端,此后服务端向客户端发送了三个报文段,第一个用于确认客户端的 SYN,后两个携带数据,因为客户端尚未发送数据给服务端,因此这里 ACK 序号都是 X+1。此时,前两个报文段都丢失了,第三个顺利到达,此时客户端会认为这第三个报文段是对其 SYN 的响应。
那么这样呢:
client ----SYN---> server
client <-ACK/SYN-- server
服务端在确认 SYN 时也向客户端发送 SYN 报文段,但是无法确认客户端收到了服务端的 ISN,因此服务端不能主动向服务端发送数据,即双向的连接尚未建立好。
长话短说,为什么不能两次握手,因为两次握手不能可靠地协商初始序列号。
连接的断开
大家都说 TCP 断开时候需要 4 次挥手,这 4 次都是什么目的呢?下面容我细细分析。
断开连接的时候,双方需要互相发送 FIN、ACK,起过程如下:
server <-----FIN-------- client
server ------ACK-------> client
server ------FIN-------> client
server <-----ACK-------- client
前面提到了连接的时候需要 3 次握手,但是实际上可以拆分成 4 次(见上文)。和上图比较,很相似。只是连接的时候发送 SYN,而断开时发送 FIN。
断开过程中双方分别发送 FIN 告知对面自己要断开连接,对端收到后发送 ACK 表示知道对方要断开。
因为 TCP 是全双工的,两端都可以主动发送数据,某一端关闭后,只是不能再写入了。但是还可以接收另一端的数据,因此,断开连接并不是双方同时进行的。这就是为什么上图中中间两个报文不能合并成一个 FIN/ACK 的道理,因此是 4 次挥手。
关于连接和断开,下面这幅图描述了 TCP 各个阶段的状态:
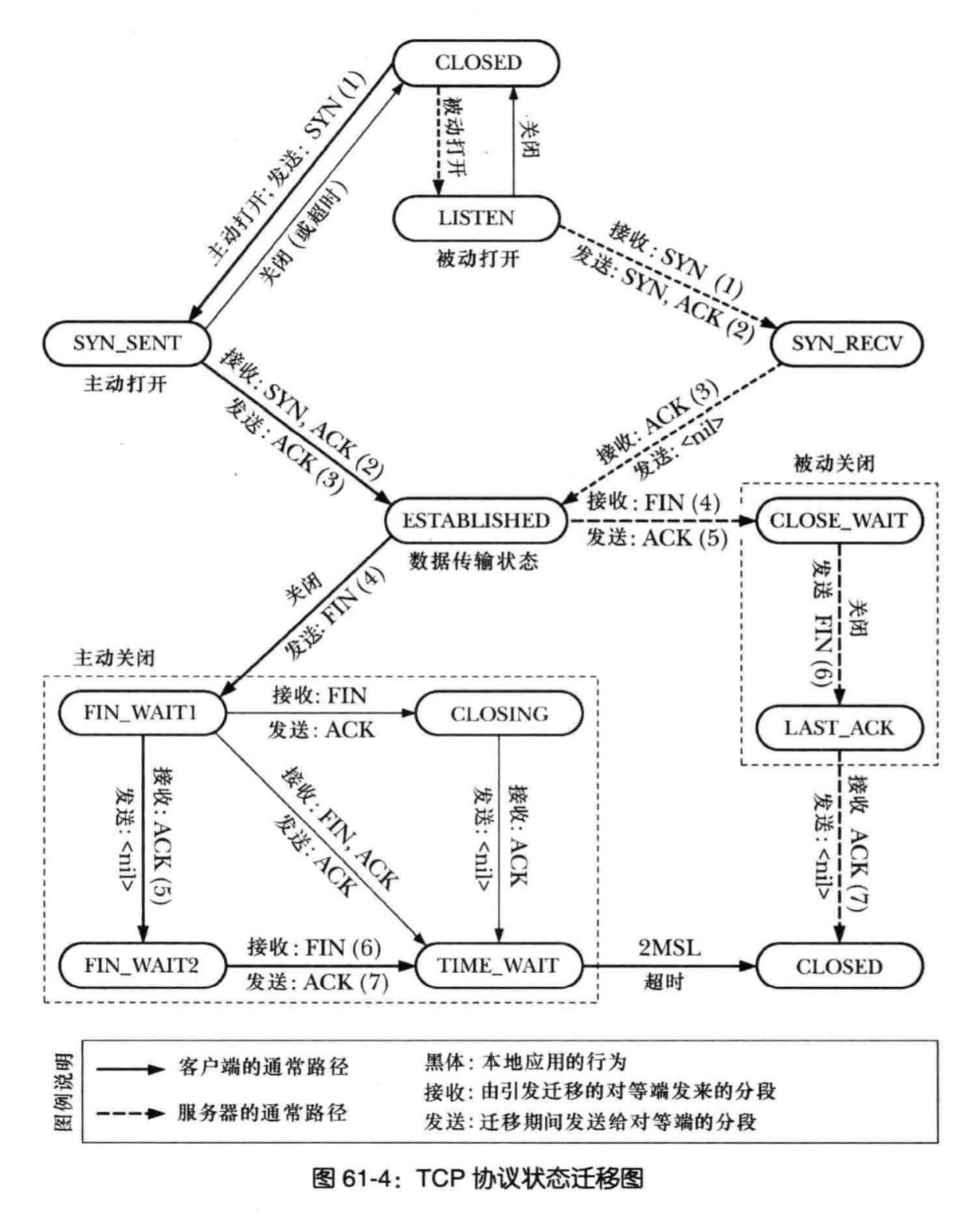
被动关闭和主动关闭
对端先发送 FIN,被称为被动关闭,反之则是主动关闭。
- 对于被动关闭:对方已经关闭了,我只需要让他知道我也关闭了就好。
- 对于主动关闭:我要对方知道我已经关闭了,同时我还要等待他关闭。
因此,对于主动关闭,只需要保证自己发出的 FIN 被确认,就可以彻底关闭了。
而主动关闭,接收到对方的 FIN 时,发送 ACK 告知对方已经收到要关闭的消息,此时进入 TIME_WAIT 状态,并没有直接关闭,而是等待 2MSL(Maximum Segment Lifetime, MSL, 报文最长生存时间)时间后,才关闭。
TIMW_WAIT 状态
主动关闭方,在发送了对对端 FIN 的 ACK 后进入此状态,原因有两点:
1. 保证对端正确地断开连接
如果最后这个对 FIN 的 ACK 丢失了,那么对端就会等到超时,然后重发 FIN,在 TIME_WAIT 状态下,可以再次对对端发来的 FIN 进行确认。如果在 2MSL 的时间里,没有收到 FIN,说明对端没有重发,表示对端收到了。
2. 保证在网络中尚未到来的数据包彻底消失
客户端断开连接后,建立了一个新连接,如果客户端使用的端口号和上次一样,那么有可能上次连接中丢失的报文段在此时到来,这就会扰乱此次连接。
因此大多数 TCP 实现规定在 2MSL 时间内,该端口不能被复用,2MSL 时间后,上一次连接的报文段已经彻底消失在网络中了,该端口就可以使用了。
端口复用
因为存在 2MSL 限制,客户端执行主动关闭后,再次建立连接时,要使用不同的端口号,通常客户端建立连接的时候是不用指定端口号的,因此操作系统会自动选择一个合适的端口号。而服务端使用的是熟知端口,如果服务器要进行重启,那么在重新复用此端口时就会出现问题,要等待 2MSL 时间,才能进行重启。当然了 socket 编程接口可以指定允许复用的选项,此时重启就不存在问题。
最大报文长度
在通信双方的 SYN 报文中,携带有 MSS 选项,它表示 TCP 传往另一端的最大数据的长度。MSS 越大,每个报文可以传输的数据就越多,网络利用率就越高。但也不是越大越好,因为要想单个报文不分段地传输,需要考虑底层的链路层协议。对于以太网,一个帧最大 1460 字节。上层发来的数据大于这个值,就要被分成多个帧发送。
如果报文分段了,那么头部就得重复一次,这是不太划算的。尤其是传输能力较弱的主机,它宁愿每次少传一点,也不愿发生分段。主机可以说明自己的 MSS,同时在发送的时候可以决定自己一次发多少数据,这样就保证拥有较小的最大传输单元 (Maximum Transmission Unit, MTU) 的机器也能保证 TCP 数据报不会分段。
拥塞控制
拥塞控制的功能是保证链路上不要出现拥堵,发现链路上出现拥堵时就应该主动减小发送的数据量。反之,链路很通畅时,就应该增大发送量。 目前整个网络能够正常运行,是网络中各个机器都遵守拥塞控制规则的结果。试想,每个设备都自顾自地发数据,都想占满整个网络中的带宽,那整个网络就堵得不成样子的。虽然运营商可以升级链路,但是再宽的链路也有被堵满的时候。
TCP 中的拥塞控制包括四个部分:慢启动、拥塞避免、快速重传、快速恢复。
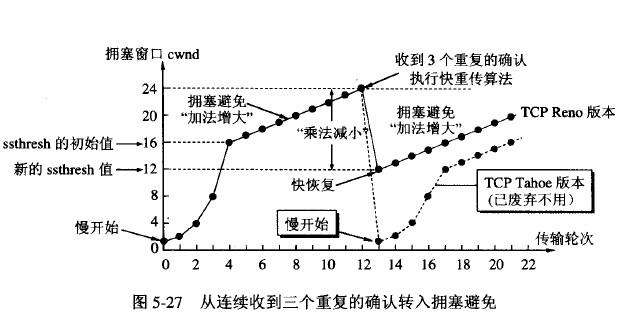
慢启动
发送方维护了一个拥塞窗口,拥塞窗口和对方的接收窗口中的最小值,就是本次发送的数据的大小。这个拥塞窗口用 cwnd 表示。
在初始阶段,并不知道通信链路的带宽有多大,先设置 cwnd 为一个报文段大小(即对端通知的 MSS 大小)。每次收到一个确认后,就把 cwnd 扩大一个报文段。在一开始,发送的速度还没有达到链路能承受的上限,会感觉 cwnd 呈指数增长。因为本次发送 n 个报文段,都收到确认后,cwnd 就扩大到 2n 个报文段了。
但是不断成倍增大,必然很快就会超出网络的运载能力,进而会导致网络拥堵。因此,存在一个门限值 ssthreth,当 cwnd 超过此值后,就进入了拥塞避免阶段。

上图中是一个慢启动的例子,在 cwnd = 3 时,为什么只发了 2 个报文段呢?因为网络中有一个报文尚未被确认,即正在发送中,cwnd 指的是网络中正在传输的报文的最大数量。
拥塞避免
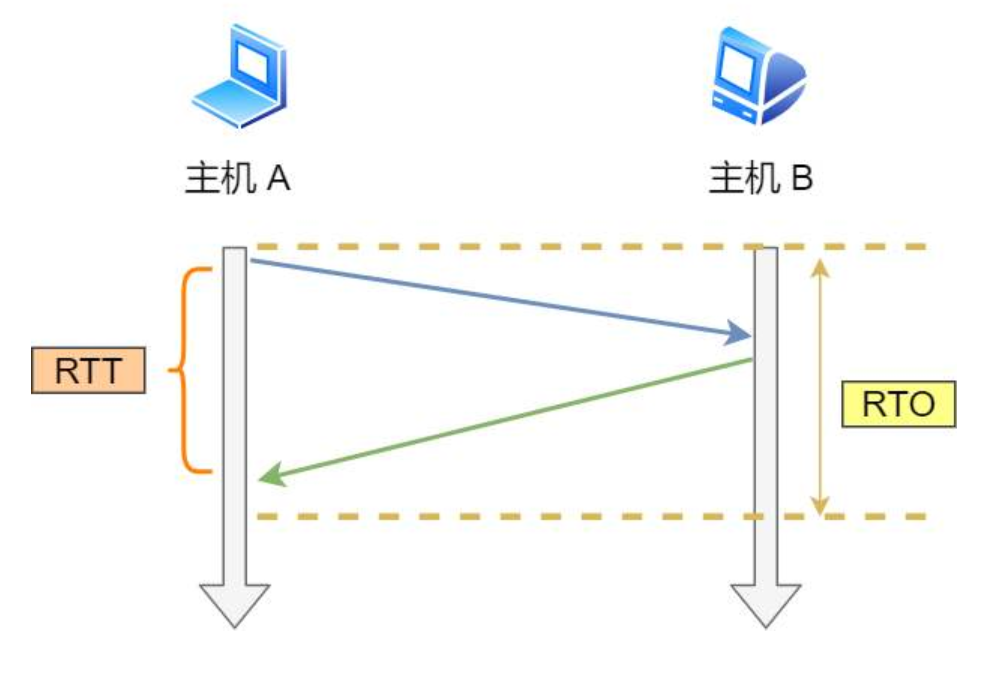
当 cwnd 扩大到 ssthreth 后,不在每个确认报文都增大一个报文段,而是每个 RTT 才增大一个报文段。RTT 是一个报文发出与收到 ACK 的时间间隔。
拥塞避免阶段慢慢地增大拥塞窗口,进一步探测链路的运载能力的上限。不断地这样增大,总有那么一个时候,会超出当前网络的运载能力,此时中间路由器开始丢弃分组。
快速重传
发送端发送的报文,需要被对端确认,发送端发送 1 2 3 三个报文,到达对方的次序可能是 2 1 3,这导致收到 2 时,会确认 ACK 1 ,收到 1 时还会 ACK 1。这种情况是报文失序了,报文失序,通常会引起一两个重复的确认。但是如果 1 号报文丢失了,之后收到的报文时都会 ACK 1。
当收到 3 个冗余的 ACK 时,认为报文丢失了,此时立刻重新发送此报文段。这叫做快速重传。出现冗余的 ACK 表示收发两端之间还是有数据流动的。此时采取的措施如下:
- 收到 3 个重复 ACK 之后,将
ssthreth设置为当前cwnd的一半,重传丢失的报文段,并设置cwnd为ssthreth加上三倍的报文段。 - 收到新的重复 ACK 时,将
cwnd增大一个报文段大小。 - 收到下一个新的非重复 ACK 时,设置
cwnd为ssthresh。这以后执行拥塞避免。
以上内容是从《TCP-IP详解卷1:协议》上看到的,不知道经过了近三十年,这一点有没有改变。
快速恢复
发送端发送了一个报文段后会启动一个定时器,如果收到该报文的确认,就关闭定时器。如果该定时器发生超时,说明有很长一段时间,该报文都没有被确认。此时网络中可能发生了严重的拥堵。这个时候就进入了快速恢复阶段。
此时采取的措施是设置 ssthreth 为当前 cwnd 的一半,并设置 cwnd 为 1 个报文段,然后开始慢启动。
流量控制
如果通信中的某一方发送数据速度过快,对方的接收缓存区就会溢出。因此,通信双方需要协商传输的流量大小。在 TCP 中,这是通过 TCP 头部的窗口大小字段实现的。通信双方会在 TCP 头部指出自己的接收窗口大小。这样对端就知道目前对方可以接受多少数据了,就不至于一次性发送很多的数据。
如果对方的接收缓冲区已经满了,那就不能再发数据了。但是什么时候可以再发呢?发送方设置一个坚持定时器周期性地查询接收对方的窗口,这叫窗口探测。
糊涂窗口综合征
如果少稍微有一点接收缓冲区,就通知发送方,发送方也发送很少的一些数据。这就导致每次传输的数据量很小,类似于一碗一碗地运水,而不是一桶一桶地运。解决方法自然是等待对方可以接受一桶水的时候再发送数据,或者自己能接收一桶水的时候在扩大自己的接收窗口。
交互数据流
经受时延的确认
如果基于 TCP 传输的是一个交互式应用,用户按下的每个键都要传输给对端,那么每次传输的内容就很少。比如每次传一个字符,那么 TCP 头部和 IP 头部就有 40 字节,而数据只有 1 个字节。这样的传输效率很低下。但是交互式应用对实时性的要求很高,因此只能容忍效率低下。
但是如果对实时性要求不高,同时又常常发送小数据,这个时候经受时延的确认就很有用。一方面,在收到数据后并不立刻确认,而是等待一段时间,在这段时间里,很可能恰好就要发送数据给对方,这个时候可以在传输数据的时候捎带 ACK。这样双方都可以避免频繁地发送小数据报文段。
Nagle 算法
Nagle 算法用于优化频繁进行小数据量传输的场景。它在同一时刻只允许网络中有一个为被确认的报文。这样,在之前发送的报文未被确认时,不能发送下一个报文。
在等待确认的这段时间,发送方可以收集到更多的待发送数据。另外,网络响应速度越快,等待时间就越短,发送数据的频率就可以越高。这种场景下,数据收集的可能还不够多,但是发送较少的数据也是可以的。相反,如果等待时间很长,说明网络环境很差,此时就可以收集到更多的数据,一次性发送更多数据,避免频繁发送小数据量的报文。
可见,这是一种自适应的算法,能够根据网络环境来动态调整发送速率。
在实时性要求很高的场景下,这种算法就不合适了。比如 X window 服务,用户每次移动数据就要立刻发送给服务器,这个时候 Nagle 算法就不适用。