数据库基本概念
数据库管理系统概述
数据库是什么?
“数据库”这个术语是指由数据库管理系统( database management syst em, 简称为 DBMS, 或称为数据库系统) 管理的数据聚集。
关系型数据库
数据库最早出现在 20 世纪 60 年代,那时的数据库是由文件系统演变而来的。后来 Ted Codd 提出关系型数据库的概念。这里的关系就是说数据应该存储在表中。对于数据如何存储,用户并不关心。数据库系统提供高级的查询语言,用户使用查询语句得到需要的数据。
比如下面是一张名为 Accounts 的表:

表的各列以属性开始,每一行都是一个元组,上图表中只显示了两个元组,每个元组中有 3 个元素。
可以使用 SQL 语句查询表中的数据。比如如果要查询账号为 67890 的账户的余额,则可以使用如下查询语句:
SELECT balance
FROM Accounts
WHERE account No = 67890;
上面这段查询语句做的工作是:
- 检查 FROM 子句给出的 Accounts 关系的所有元组;
- 选出满足 WHERE 子句给出的某个判别条件的元组;
- 将这些元组按 SELECT 子句指定的某些属性组织成结果输出。
数据库系统的组成与结构
数据库系统应该由下列几部分组成:
- 数据定义语言,用来建立数据库和规定数据的格式
- 数据查询语言,用来查询或更新数据
- 支持存储大量数据的存储系统
- 对多用户访问的支持,用户之间访问不受彼此影响
其结构大致如下图:
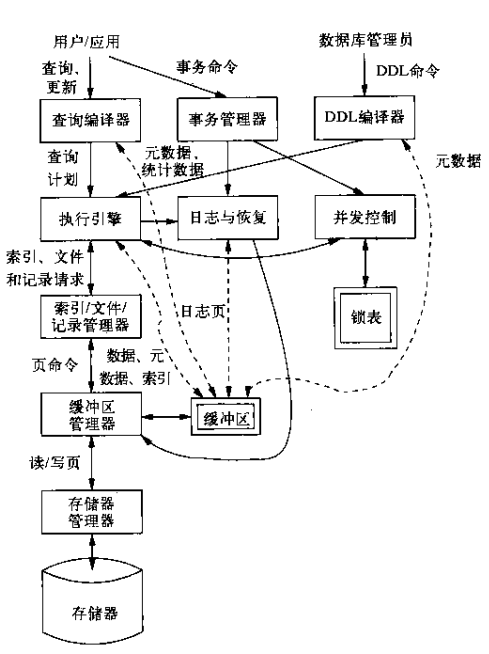
数据库管理员通过数据定义语言(DDL)来建立表,以及给表中添加各个列,以及确定它们之间的关系。相当于建立一张空的某种表格一样。
用户通过数据操作语言(DML)来从表中检索信息,添加、修改或删除信息,但是不能对表的结果做改变。用户提交的每个操作指令被组织成事务,事务是原子性的执行单位,各个事务之间要相互隔离。
每个事务都会被记录在日志中,日志管理器可以保证任何时候数据库系统崩溃后,通过日志都能完成恢复。

关系数据库模型
数据模型
数据模型用于描述数据或信息,它由三部分组成:
- 数据结构:这里的数据结构不同于 Java 等编程语言中的数据结构,而是指数据存储在物理磁盘上的数据块中的结构。
- 数据操作:对数据结构的操作,如删除、修改、查询等。
- 数据上的约束:对数据的约束条件,比如对于星期数,只能是 1-7 之间的数字。
关系模型
关系模型提供了一种单一的描述数据的方法:一个称为关系的二维表。如下图所示:

该表就是一个关系,其名称为 Movies,其中每一行为一部电影的信息。下面是与关系相关的术语:
属性
关系中每一列命名为一个属性,比如上图中属性分别为 title, year, length, genre。属性应该描述该列的含义。属性是集合,而非列表,看起来有先后次序,实际上只是书写的需要。
模式
关系名和其属性集合的组合称之为关系的模式。描述模式通常是使用 关系名(属性) 这样的方式,如:Movies(title, year, length, genre)。
元组
关系中除了属性所在行的其他行都被称为元组,每个元组都有一个与关系的每个属性相对应的分量。
域:
元组中的每个分量都应该是最基本的内容,如 integer 或者 string,而不能是列表、集合等。关系中每个属性都属于一个域(或类型),元组对应该列的分量必须也是这种类型。
关系实例
一个给定的关系中的元组的集合叫做关系的实例。
键
在关系模型中可以增加一些约束,其中一种就是键约束。关系可以选择一个或者几个属性的集合作为键。每个元组中对应于键的属性的值不能相同。比如每个元组中含有一个身份证号,那么身份证号这个属性就能作为键,因为在每个元组中它都是不同的。
在 SQL 中定义关系模式
SQL 中的关系
SQL 区分三类关系:
- 存储的关系
- 视图
- 临时表
数据类型
char 与 varchar
CHAR(n) 表示最大长度为 n 的字符串,当实际插入的字符串长度小于 n 的时候,会使用空格填充,因此占据的空间就确确实实是 n 个字节。而 VARCHAR(n) 也表示最大长度为 n 的字符串(严格模式下),存储字符串时会在字符后面用一个或多个字节来存储字符串的长度,如果实际长度小于 n 那么实际占据的空间是字符串长度加存储字符串长度所需的空间。CHAR 的优势是查找的时候速度快,就是会浪费一些存储空间。而 VARCHAR 则是牺牲了速度来换取空间。
BOOLEAN
布尔类型可能的取值有 TURE、FALSE 和 UNKNOWN
代数查询语言
关系代数
传统关系代数的操作主要有以下四类:
- 通常的关系操作:并、交、差。
- 除去某些行或列的操作:“选择”用于消除某些行,“投影”用于消除某些列。
- 组合两个元组:“笛卡尔积运算”,“连接”(JOIN)操作。
- 重命名:改变属性名称。
集合操作
三个常见的集合操作是:交、并、差。对于相同的关系,可以使用这几种操作,得到新的元组集合。
R ∪ S:表示关系 R 和 关系 S 的并,结果是出现在 R 和 S 中的所有元组的集合。R ∩ S:表示关系 R 和 关系 S 的交,结果是同时出现在 R 和 S 中的元组的集合。R - S:表示关系 R 和 关系 S 的差,结果是在 R 中出现,但不在 S 中出现的元组的集合。
投影
投影是从关系 R 中生成新的关系,这个关系只包含原来关系 R 中的部分列。
选择
选择操作是通过一个条件,选择满足条件的所有元组。
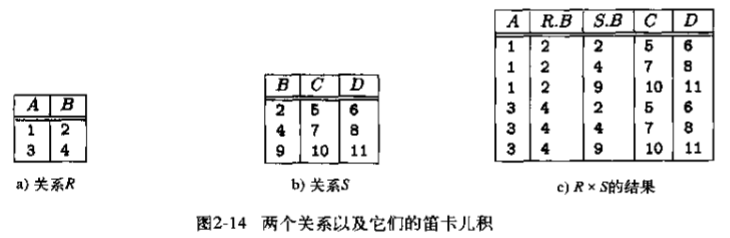
笛卡尔积
关系 R 和关系 S 的笛卡尔积是一个有序对的集合,有序对的第一个元素是关系 R 中的一个元组,第二个元素是关系 S 中的一个元组。结果是 R 和 S 关系模式的并。如果有相同的属性,则使用关系名作为前缀。
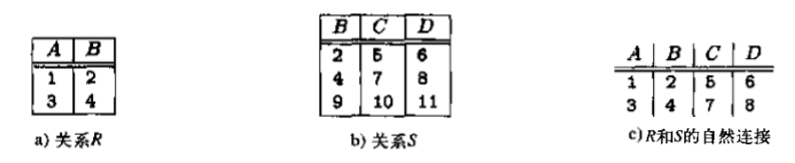
自然连接
自然连接是通过两个关系中元组的某公共属性来将两个元组连接成一个。
θ 连接
θ 连接中的 θ 是指任意条件,关系 R 和 S 的 θ 连接的结果是先得到 R 和 S 的积,而后寻找满足条件的元组。
各种集合操作组合起来就能构成复杂的查询语句。
关系数据库设计理论
函数依赖
函数依赖的定义
关系 R 上的函数依赖是指,R 中元组的属性 A1, A2 等部分属性决定了其余属性,即 A1,A2 定下来后,其余属性的值也就确定了,就像有一个函数将 A1,A2 作为输入,输出为其他属性。
关系的键
关系的键是元组的一个属性或多个属性的集合,关系的键在所有元组中应该是唯一的,即不存在两个元组其键是相同的。键函数决定了关系中所有其他属性。
超键
含有键属性的属性集合,比如属性 A 是键,那么加上属性 B 后 {A,B} 自然也是键,这个 {A,B} 就叫做超键。
关系数据库模式设计
异常
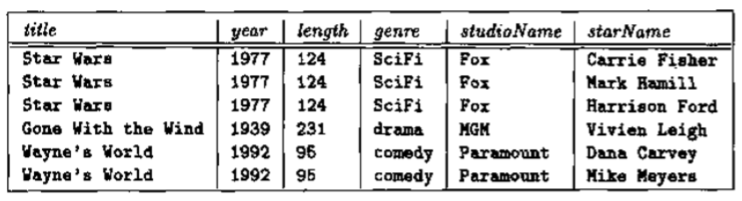
当试图在一个关系中包含过多信息时,产生的问题成为异常,异常类型分为:
- 冗余:信息没有必要再多个元组中重复,如上图中为了存储一部电影的所有演员,则把每部电影的时长,发行年份等信息重复了多次。
- 更新异常:更新了某个元组的信息,但是没有更新其他元组中该修改的信息。
- 删除异常:如上表是用来存储一部电影的所有演员信息的,但是如果删除了 Gone With the Wind 的演员信息,这一行也就被删除了,数据库中就再也没了这部电影的其他信息。
分解关系
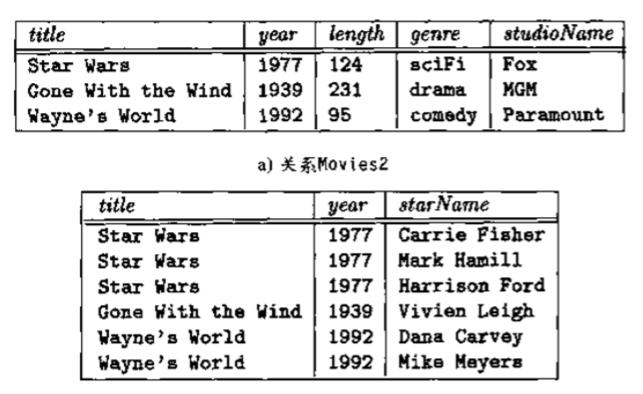
可以通过将关系分解为多个关系来消除许多异常。分解的目的是将一个关系用多个不含有异常的关系代替。
范式
BCNF
关系 R 属于 BCNF 当且仅当:如果 R 中非平凡 FD } 是关系 R 的超键。也就是说,关系 R 中有一个超键,这个超键能够确定其他所有属性。
比如,上图中,{title, year} 或者 {title, year, length} 都不能确定 starName 这个属性,因此该关系不属于 BCNF。
而上面这幅图中 {title, year} 就可以唯一确定其他所有属性。因此这两个关系都属于 BCNF。属于 BCNF 的关系,就不会存在冗余
第一范式
符合 1NF 的关系中的每个属性都是原子的。
第二、三、四范式
看不懂,后面换本书继续看。
代数和逻辑查询语言
包
前面都是把关系实体看做是元组的集合,现在将关系实体看做元组的包,这意味着允许多个相同的元组出现在包中。采用包的好处是,在进行并、交、差等操作时根据方便,不需要考虑重复。
扩展操作符
消除重复
把包转换为集合,即消除包中重复的元组。
聚集操作符
用来处理所有元组的某一列,比如 SUM 操作用来计算某一列的和。其他的操作有:
AVG:求某一列的平均数MIN:求某一列的最小数MAX:求某一列的最大数COUNT:求某一列中元素数量
分组
能够根据某个属性,将相同的值分组在一起。