使用 Doc2Vec 来做情感分析
文档的向量表示
常见的对句子、段落或者文档进行建模的方法包含 bag-of-words (BOW)、bag-of-n-grams、词向量加权求和等,它们都存在着一些问题,具体说来:
bag-of-words (BOW) 模型
失去了语序,不同的句子可能有完全相同的表示,没有考虑到语义。
bag-of-n-grams
即使考虑到了短距离的上下文,但是常常面临数据稀疏性和维度过高的问题。
词向量加权求和
对句中的词的词向量做加权求和:失去了语序。
本次机器学习大作业,尝试使用了了一种叫做 Paragraph Vector 的文档表示方法,可以把句子、段落、文章表示为一个固定维度的向量,并且克服 bag-of-words 的缺点。在论文[Distributed Representations of Sentences and Documents]中有详细介绍。
算法细节
Paragraph Vector 的构造方法和 Word Vector 的构造有很多相似之处。
词的向量表示
每一个词用一个向量表示,字典里的所有词的向量构成一个矩阵,每个词的词向量对应矩阵中的一列,这一列的索引是该词在字典中的位置。这个模型的思路是使用前面出现的词来预测接下来的词。比如 the cat sat on the table,该模型输入 the cat sat 这三个词的词向量,期待的输出是 on 的词向量。
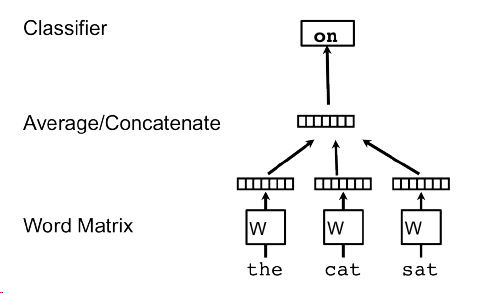
图一. 训练词向量的模型。输入为 “the” “cat” “sat” 三个词的词向量(矩阵 M 中的某一列),然后将这三个向量求平均或者拼接,期望的输出为接下来紧跟着的词 “on”。
虽然这些向量都是随机初始化的,但是在训练的过程中,它们会逐步调整,最终能够具备语义信息。训练完成后,具有相似意义的词会具有相似的向量表示,即语义具有相似性。
文档的向量表示:分布式记忆模型
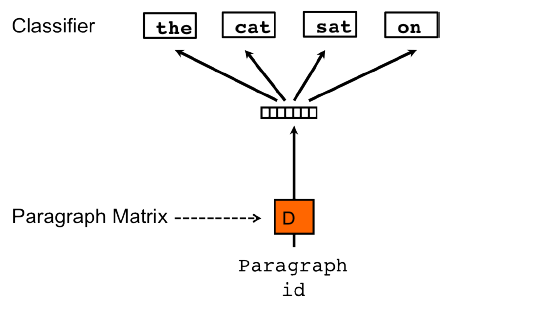
Paragraph vector 的训练和 word vector 的训练有很多相似之处。不同在于每一个段落对应一个向量,所有段落的向量作为列构成一个矩阵 D。所有的词依然构成矩阵 W。在做预测的时候,把句子的向量和词向量做拼接或者加和作为输入。

图二. 训练段落向量的模型。
这里句子的向量,可以看做是另外的一个词,这个词记录了当前上下位中缺失的部分,即为了得出预期的预测结果,输入的向量中应该补充点什么。这样以来句子的向量中就包含了整个句子的语义信息。
在训练的过程中,一个 paragraph vector(即 D 中的一列)用于对一个句子的训练,即滑动窗口在这个句子上滑动时,会更新该句子对应的向量。词向量构成的矩阵 W 在所有句子的训练过程中共享。
训练完成后,矩阵 D 中每一列对应的 paragraph vector 可以作为这个句子(或段落,文档)的特征向量。然后就可以使用逻辑回归、支持向量机等方法来完成具体的机器学习任务了。
但在预测阶段,出现的句子是在训练过程中未见过的。这时候,就采用之前训练过程中产生的模型,再对一个句子进行训练得到该句子的词向量即可。
文档的向量表示:分布式词袋模型
这个模型选择一个窗口,以 paragraph vector 作为输入,期望输出为窗口内的词。实际操作中,通常是在窗口内随机选择一个词,期待分类器输出这个词。然后利用随机的梯度下降来更新 paragraph vector。在这个过程中 paragraph vector 中能够捕捉到句子的一些句意,但是忽略了语序。
实验过程
本节尝试采用上文提到的文档的向量化表示方法来进行情感分类。基本步骤如下:
- 数据预处理
- 训练 Doc2Vec 模型,将评论向量化
- 采用全连接神经网络来进行分类
训练 Doc2Vec 模型
上文提到的文档向量化表示的方法,在 gensim 这个自然语言处理库中提供了相关的工具,这里采用 gensim 中的 Doc2Vec 模型来完成对影评的嵌入。
gensim 中 Doc2Vec 的输入为 TaggedDocument 的列表,TaggedDocument 的形式形如:
[['word_1', 'word_2', 'word_3',..., 'word_n'], ['label_1']]
即由文档中的单词和文档的标签构成。训练完成后可以使用文档的标签来提取该文档对应的向量。
这里首先将各条评论经过预处理后分割为单词序列,而后构建 TaggedDocument 的实例:
def build_tagged_document_list(docs):
tagged_docs = []
for i in range(docs.shape[0]):
doc = docs.iloc[i]
line= doc.review
tag = doc.id
tagged_docs.append(gensim.models.doc2vec.TaggedDocument(gensim.utils.simple_preprocess(line), [tag]))
return tagged_docs
train_docs = build_tagged_document_list(train_sentences)
unlabel_docs = build_tagged_document_list(unlabel_sentences)
test_docs = build_tagged_document_list(test_sentences)
使用 gensim.models.doc2vec.Doc2Vec 构建模型:
all_docs = train_docs + unlabel_docs + test_docs
random.shuffle(all_docs)
doc2vec_model = gensim.models.doc2vec.Doc2Vec(min_count=1,
window=10,
vector_size=400,
sample=1e-4,
negative=5,
workers=32,
epochs=20)
doc_model.build_vocab(all_docs)
doc2vec_model.train(all_docs, total_examples=doc2vec_model.corpus_count, epochs=doc2vec_model.epochs)
使用训练好的 doc2vec 模型得出训练 review 的向量表示:
def get_doc_vec_list(doc_model, docs):
vector_size = 400
vectors = np.zeros((docs.shape[0], vector_size))
for i in range(docs.shape[0]):
doc = docs.iloc[i]
tag = doc.id
vectors[i] = doc_model[tag]
return vectors
X = get_doc_vec_list(train_sentences)
y = train_sentences['sentiment'].astype('float')
使用 keras 构建神经网络模型:
from keras.utils import to_categorical
from keras import layers
from keras import models
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(400,)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
return model
model = build_model()
对模型进行训练:
history = model.fit(X_train,
y_train,
epochs=30,
batch_size=512,
validation_split=0.3)
查看误差变化:
import matplotlib.pyplot as plt
epochs = 30
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(range(epochs), loss, label="loss")
plt.plot(range(epochs), val_loss, label="val loss")
plt.legend()
plt.savefig('loss.png')
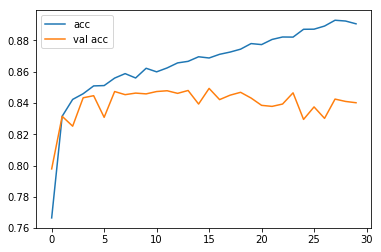
由上图可以看出,当进行到第十五个 epoch 的时候,在验证集上的精度开始下降,开始出现过拟合。
重新训练模型,并对测试数据进行预测,最终得到了 84.34% 的准确率。
小结
基于 skip-gram 的思想,对句子或文档做嵌入得到的文档的向量表示,该向量在一定程度上能够反映出句子的含义。
为了确定 Doc2Vec 在此场景下是否能够很好地做 review 的特征提取,这里采用了同样的数据,拿 Logistic Regression 做分类器,在验证集上得到了 85.05% 的精度。可见使用 Doc2Vec 对 review 做特征提取,本节在情感分类的任务上尝试使用 Doc2Vec 模型,得到的效果并不令人满意。
分析其原因,可能是因为单条评论的长度较长 (平均 233 词),Doc2Vec 可能并不能很好地对如此长的句子进行嵌入。