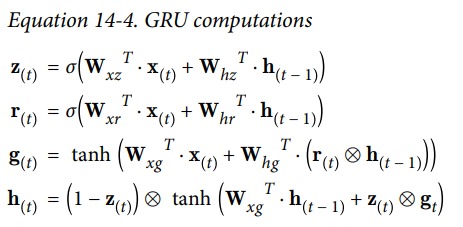循环神经网络
本文是阅读 Hands-On Machine Learning with Scikit-Learn and TensorFlow 第 14 章记录的笔记,总结了常见基础 RNN,LSTM 和 GRU 的网络结构,并描述了它们为什么要那样设计。
RNN
Recurrent neural networks (RNN) 一种号称能够预测未来的网络模型,其实质是输入一个序列,预测接下来的序列。基础的 RNN 的模型非常恨简单,他看起来像是一个全连接网络(下图左),它的输入由两部分构成,当前输入 $x_{(t)}$ 以及上一个时刻的输出 $y_{(t-1)}$。
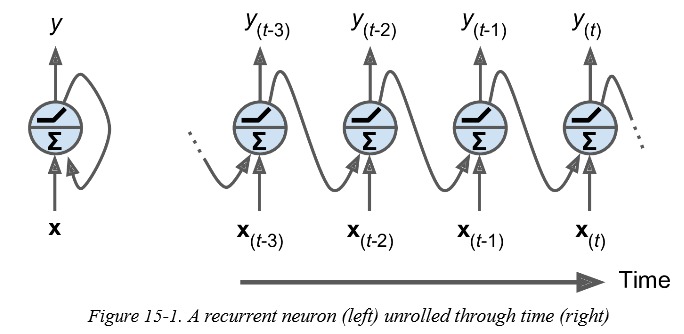
把序列中的各个元素 $x_{(i)}$ 连同上一时刻的输出 $y_{(i-1)}$ 一并输入给 RNN,得到新的输出 $y_{(i)}$。连同此输出再与序列中下一个元素一并输入 RNN,再次产生新的输出。整个过程就像编程语言中的 for 循环一样,在对一个序列进行处理是,每次循环都用到了前一次循环的状态,以及序列中下一个元素。
RNN 的数学表达式如下:
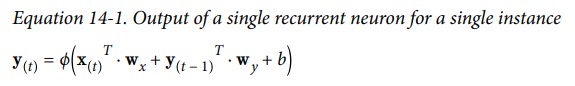
虽然 RNN 的结构让它可以处理无限长的序列,看起来能够捕获跨度很长的模式,但受限于 RNN 简单的结构,序列信息在每一个 time step 都会丢失,RNN 往往也只能捕获短距离的模式。为了解决信息遗忘的问题,很多 RNN 的该键版本被提出,比如 LSTM、GRU,这些改进版本都引入了长期记忆模块。这些具有长时记忆模块的 RNN 结构在实践中被证明很有用,基础版本的 RNN 已经不在被使用了,现在提到 RNN 人们首先想到的会是 LSTM 和 GRU。
LSTM
Long Short-Term Memory (LSTM) 于 1997 年被提出,之后经过一些改进。它引入长时记忆模块,能够捕获到序列中长距离的依赖关系,在训练中收敛速度比基础版本的 RNN 快。LSTM 的结构如下图所示:
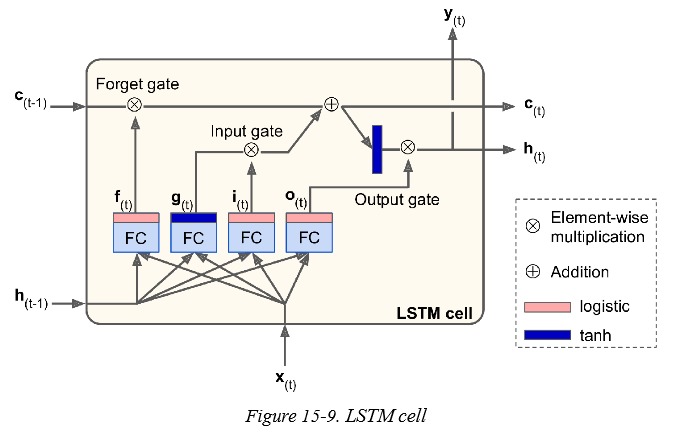
它的状态分为两部分,$h_{(t)}$ 和 $c_{(t)}$ , $h_{(t)}$ 是短时状态,$c_{(t)}$ 是长期状态,这里 $c$ 和 $h$ 都是向量。其主要思想是,LSTM 能够学习把什么存入长期状态,把什么从长期状态中扔掉。$c_{(t-1)}$ 先经过一个遗忘门,丢去一些记忆,然后再加上一些信息,得到新的状态 $c_{(t)}$。新的状态 $c_{(t)}$ 会经过一个 $tanh$ 函数,得到的向量被 output gate 选择后做为当前 time step 的输出,和新的短时状态 $h_{(t)}$。
可以看到 LSTM 的输出是依托于长期状态 $c_{(t)}$ 的,而 $c_{(t)}$ 在每个 time step 会丢掉一些信息,再加入一些信息。控制如何丢弃,如何加入,最终输出什么,由 3 个门控制。加入什么信息由 $g_{(t)}$ 控制。而这些的输入都是 $x_{(t)}$ 和 $h_{(t-1)}$。
$x_{(t)}$ 和 $h_{(t-1)}$ 经过 4 个全连接网络输出 4 个向量,这 4 个向量有不同的目的:
$g_{(t)}$ 对应的全连接网络分析当前输入 $x_{(t)}$ 和前一个短期状态 $h_{(t-1)}$ 之间的关系,得到一个输出用于向长期状态中增加信息。
其他的三个门 $f_{(t)}$、$i_{(t)}$、$o_{(t)}$ 分别被称为遗忘门、输入门、输出门,它们是由 sigmoid 激活函数输出的,其元素的值介于 0~1 之间。
- 遗忘门,控制长期状态中那些部分需要被遗忘。$f_{(t)}$ 和 $c_{(t-1)}$ 做对应元素向量,如果遗忘门的中元素为 1,那就是不遗忘,如果为 0,那就是遗忘。
- 输入门,控制 $g_{(t)}$ 中那些部分加入长期状态中。
- 输出门,在 $c_{(t)}$ 经过 $tanh$ 后,输出门控制那些信息会被输出。
LSTM 能够识别到一个重要的输入,并将该输入的信息存入长期状态中。状态 $c$ 保留长期信息用于之后使用,并在合适的时刻将长期状态中的部分信息遗忘掉。这就是 LSTM 能够捕获序列中长距离模式的原因。
LSTM 的数学表达式如下:

Peephole connections
从前面的描述可以看出,LSTM 在计算各种门的输出时,只用了 $x_{(t)}$ 和 $h_{(t-1)}$,但有人觉得如果能够用到 $c_{(t-1)}$ 岂不更好。因此在 2000 年研究者提出了一个改进,将 $c_{(t-1)}$ 加入输入门和遗忘门的计算,把 $c_{(t)}$ 加入输出门的计算。
GRU
Gated Recurrent Unit (GRU) 于 2014 年被提出,是一种简化版本的 LSTM。其模型结构如下:
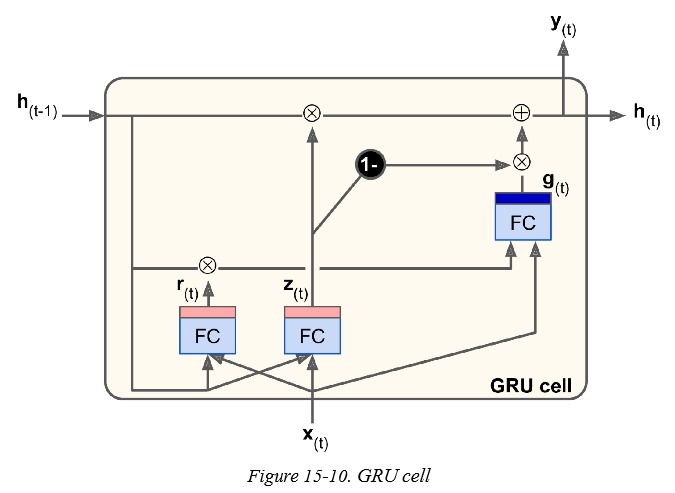
相比于 LSTM,GRU 有以下改变:
- 只使用了一个状态 $h_{(t)}$。
- 使用一个门 $z_{(t)}$ 同时控制输出门和遗忘门,当遗忘了信息时($z_{(t)}$ 为 0),那么就会输入信息(1-$z_{(t)}$ 为 1,注意图中黑色写着 -1 的圆圈)。当状态中的某个维度被遗忘后,就一定会加入新的信息。
- 去除了输出门,但是加入了新控制门 $r_{(t)}$ 对参与运算的状态 $h_{(t-1)}$ 做了过滤。
GRU 的数学表达式如下: