训练深度网络
优化器
Momentum
模拟石头滚下山的状态。在平坦的函数平面上因为有加速度的存在,能够快速通过平坦区域。

optimizer = keras.optimizers.SGD(lr=0.001, momentum=0.9)
Nesterov Accelerated Gradient

在计算新的梯度时,考虑到已经加入的动量。
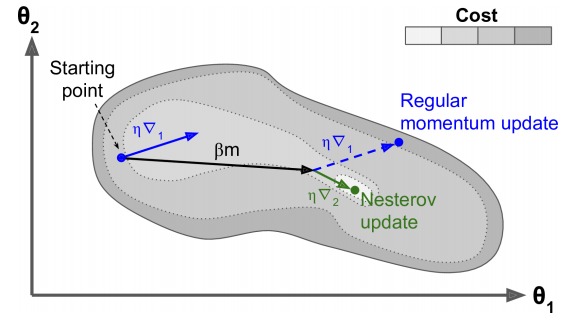
optimizer = keras.optimizers.SGD(lr=0.001, momentum=0.9, nesterov=True)
AdaGrad
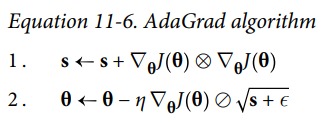
梯度小的方向,大幅更新。梯度大的方向,小幅度更新。
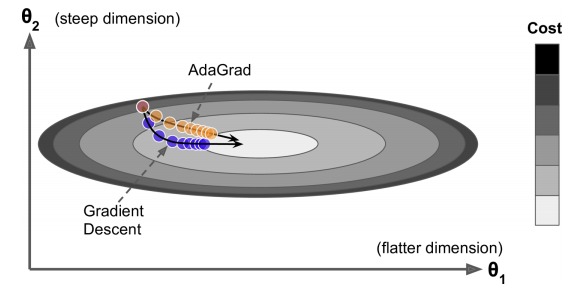
上图中,水平方向较长,较平坦,梯度较小。竖直方向,梯度较大。常规的梯度下降法,会走蓝色路径。而 AdaGrad 会走橙黄色路径。
但是 AdaGrad 不断地对梯度值进行累加,最终导致上面式子中 s 的值过大,更新越来越慢。
RMSProp
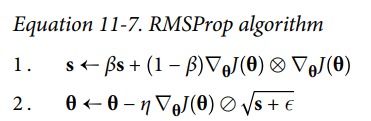
RMSProp 修复了 AdaGrad 的问题,通过引入一个衰退系数,让 s 仅仅累加最近的梯度。
optimizer = keras.optimizers.RMSprop(lr=0.001, rho=0.9)
Adam and Nadam

Adam 综合了 RMSProp 和 Momentum。3 4 两个式子中 t 代表的是迭代次数,当迭代次数较小的时候,m 和 s 的值能够被放大,当迭代次数增大是分母也就很接近 1 了,m 和 s 的值就不会在被放大了。这是为了在迭代的初始时,m 和 s 的值为 0,通过这两个式子,可以对初试阶段进行加速。
optimizer = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
Nadam 是在 Adam 中加入了 Nesterov Accelerated Gradient 中的思想。
梯度消失 / 梯度爆炸
误差梯度在反向传播的过程中,变得越来越小,最后近乎消失,这导致网络的前面的层对应的参数得不到更新。相反,梯度也可能变得越来越大,在反向传播的过程中,梯度越变越大,最终模型无法收敛。
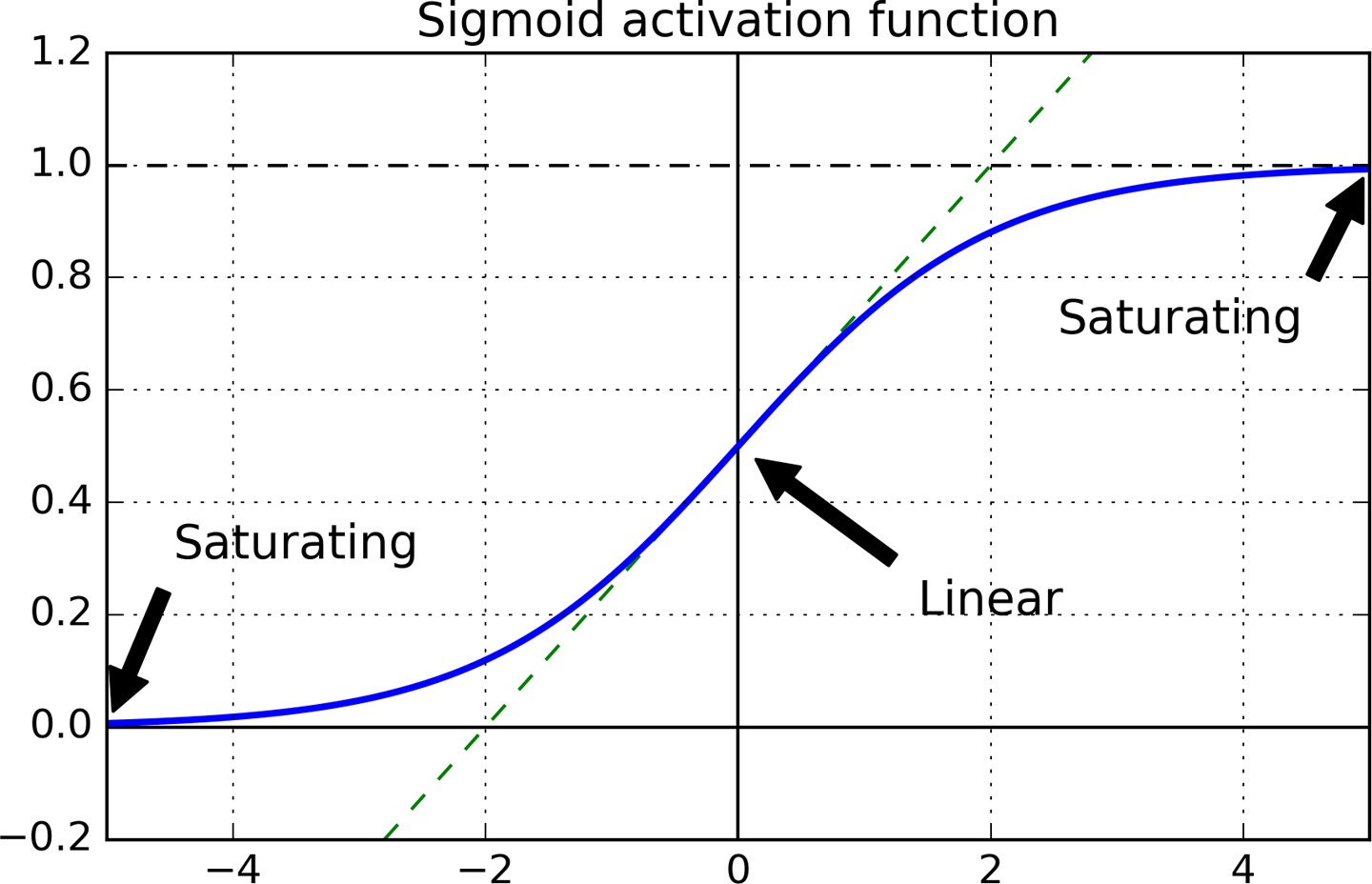
梯度消失的原因主要是使用 sigmoid 作为激活函数导致的,sigmoid 函数当输入很大或很小时,其梯度都接近于 0。
Relu 激活函数的问题在于,一旦某个 unit 输出小于 0,那么它之后就只会输出 0,而且梯度也会是 0,即 ReLU 也可能出现梯度消失的问题,此 unit 的权重将得不到更新。这个问题称为 Dead ReLUs。
梯度爆炸常常出现在循环神经网络中。为啥
Batch Normalization
使用 ReLU 及其变种,加上合适的参数初始化策略,在训练的初期可以很好地消除梯度消失/爆炸的问题,但不能保证在整个训练过程中都不出现梯度消失/爆炸的问题。Batch Normalization 对输入的整个 batch 的数据做标准化,可以持续减缓梯度消失/爆炸的问题。
Batch Normalization 需要调整的参数不多,momentum 用于计算动态调整的均值,它的值应该接近于 1。样本集越大,或者 batch-size 越小时,momentum 应该越接近于 1。
如果在输入层之后紧接一个 batch normalization 层,对数据做标准化操作就可以不用显式地完成了。
梯度裁剪
梯度裁剪是限制梯度的大小不超过某个阈值。在 RNN 中梯度裁剪尤其重要,因为 RNN 常常出现梯度爆炸的问题。
optimizer = keras.optimizers.SGD(clipvalue=1.0)
model.compile(loss="mse", optimizer=optimizer)
在 keras 中设置梯度裁剪尤其简单,以上代码将限制梯度的绝对值小于 1.0。对梯度的某个分量进行裁剪,会导致梯度方向的改变,比如原梯度为 [100, 1], 裁剪后变为 [1, 1],这极大地改变了梯度方向。要想保证梯度方向不变,可以对梯度的 L2 范数做限制,即限制梯度向量的模长。下面的设置保证梯度的模长不大于 1,否则各个分量都进行缩减,保证梯度方向不变。
optimizer = keras.optimizers.SGD(clipnorm=1.0)