论文解读 - Attention Is All You Need
本文详细解析 Google Brain 于 2017 年发表的论文 《Attention Is All You Need》中的提出的 Transformer 模型。
本文的内容参考了原论文,李宏毅老师讲 Transformer 的课程,以及 Aurélien Géron 的书籍 Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow 中讲 Transformer 的相关章节。
本文的图来自原论文、李宏毅老师的 PPT、Aurélien Géron 的书,感谢他们。
前言
在 Transformer 之前,Seq2Seq 模型中常使用 RNN 来进行编码和解码,另外也有使用 CNN 来的。但是 RNN 和 CNN 都存在明显的缺点。RNN 由于依赖上一时刻的输出,难以做到并行化,速度往往很慢。而 CNN 因为卷积核只能覆盖序列中的一部分,无法捕获长距离依赖的关系,要想能够捕获长距离的依赖关系,需要叠加很多层的 CNN。
这篇论文中提出的 Transformer 模型使用 Attention 机制来对序列中任意输入元素间的依赖进行建模。RNN 中长距离的依赖关系需要跨越很多个时间步,而 Transformer 中依赖关系更加直接。而且 Transformer 可以高度并行化地运行,无论是训练速度相比 RNN 大幅加快。
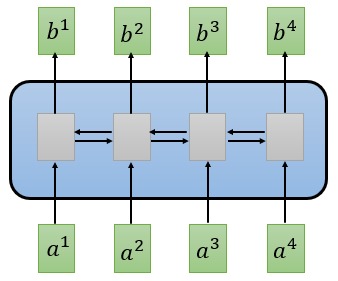
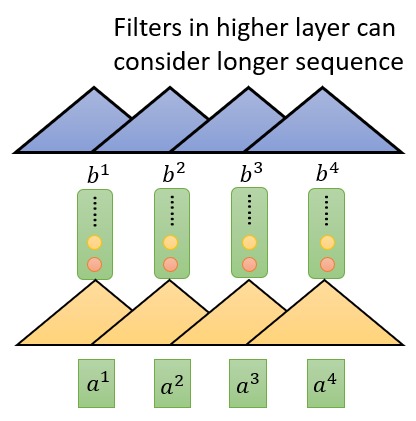
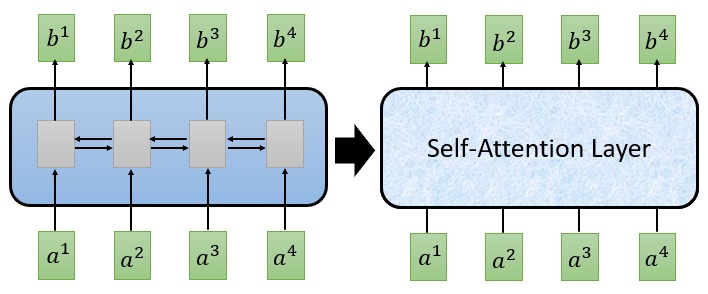
Transformer 利用 Self-Attention 机制改善了 RNN 和 CNN 模型中存在的问题。 Self-Attention 层的输入和输出和 RNN 序列模型相似,任何可以使用 RNN 的地方都可以替换成 Self-Attention 层。而 Transformer 就建立在 Self-Attention 层的基础上。
Transformer 结构
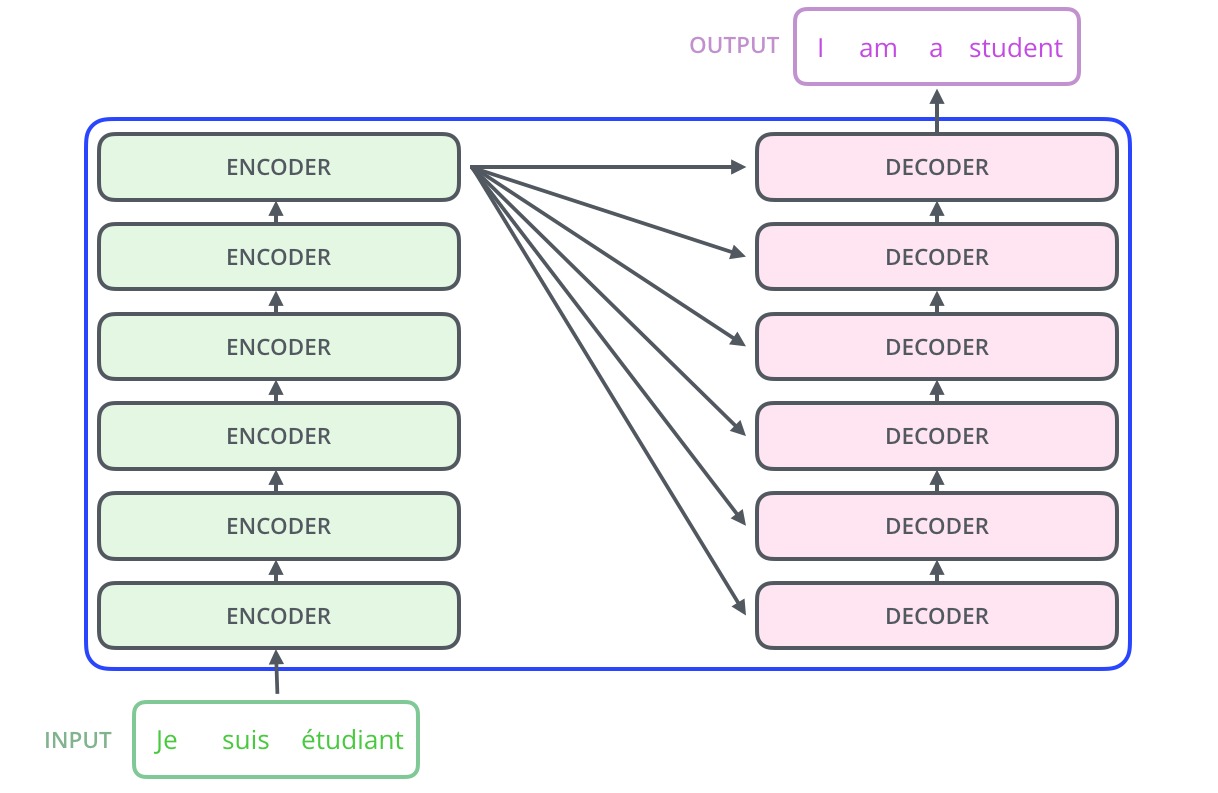
Transformer 本质上是一个 Encoder-Decoder 模型,他内部使用 Self-Attention 来对序列进行编码和解码。Transformer 的网络结构如下:
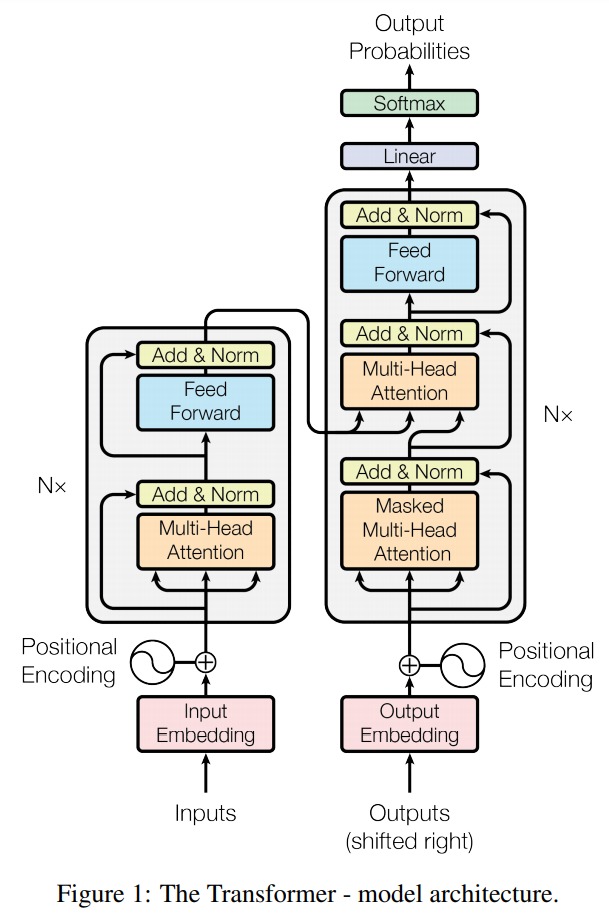
左边是 Encoder,其中 Nx 表示方框中的部分可以重复 N 次,这就相当于 RNN-based 的 Encoder-Decoder 模型中 RNN 也可以是多层的一样。
论文的作者好像觉得大家都能轻易看懂上面的图,论文中对网络模型的细节没有太多描述。因此我第一次看此论文的时候完全不知道这是在干吗,过了还几个月,听好多人谈论这个模型才算是有了一些认识,最后看李宏毅老师的课程时,对它认识又深入了一层。
下面对模型中各个部分进行详细讲解:
Encoder
先来看 Encoder 部分,输入是 token 序列,每个 token 都有唯一的编号,经过 Embedding 层后,每个 token 转换为低维稠密向量。Positional Encoding 是给输入中加入位置信息,这个后面再谈。然后经过 Multi-Head Attention,Add & Norm, Feed Forward 等模块,最终完成对输入序列的编码。
这里 Encoder 的输出和之前基于 RNN 的 Encoder 没有差别,都是输出一组向量,然后交给 Decoder 处理。下面面讲详细讨论 Encoder 中的组件,继续往下看吧。
Multi-Head Attention
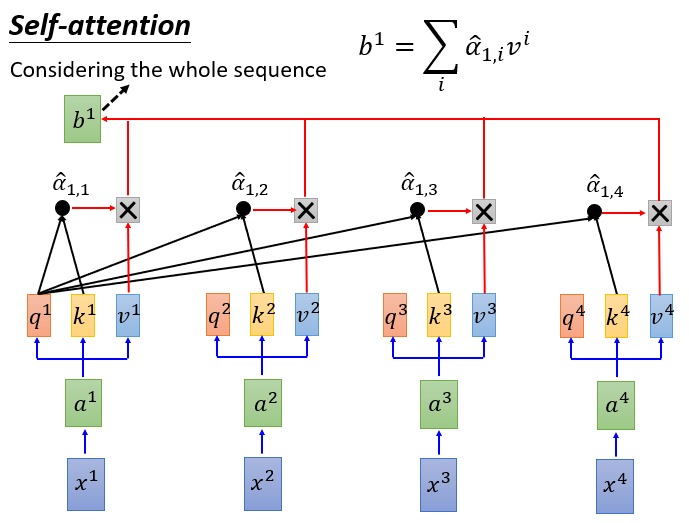
考虑 Attention 的常规做法,使用一个向量 A 去与另外一些向量 B 求一个权重,然后使用这个权重对 B 做加权和,得到一个向量。这篇论文中对 Attention 做了更加广义的描述,使用一个 Query 去和一组 Key-Value 对的 Key 进行匹配,匹配得到一个权重,然后对 Value 做加权求和,得到 Attention 的结果。
Multi-Head Attention 的结构如下:
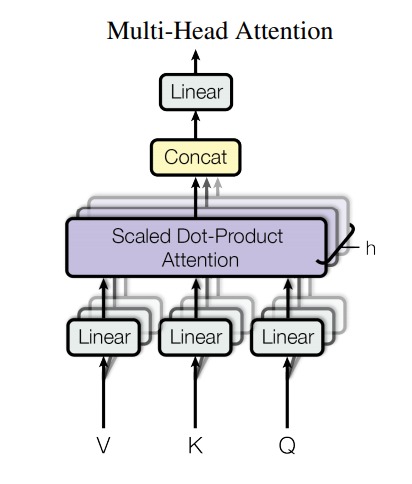
图中的 V,K,Q 正是前提到的 Value, Key 和 Query。这里的 V,K,Q 怎么来的呢?看下图:
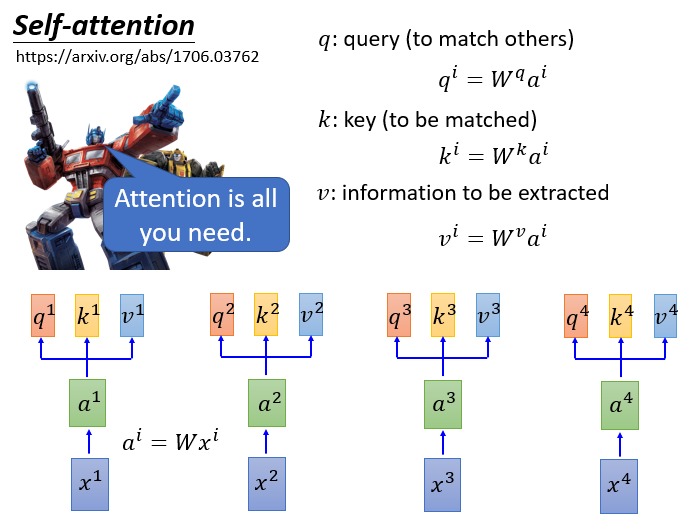
输入向量(token 经过 Embedding 得到)乘上一个三个不同的矩阵就得到了 q,k,v,即 query, key, value,这是输入向量经过线性变换得到的新向量。此处的三个矩阵 $W^q$, $W^k$, $W^v$ 是模型需要学习的参数。输入序列中的每个 token 都对应各自的 q,k,v。这里 q,k,v 的维度都相同,一个 token 的 query 就可以去 match 其他 token 的 key,然后对 value 做加权和。
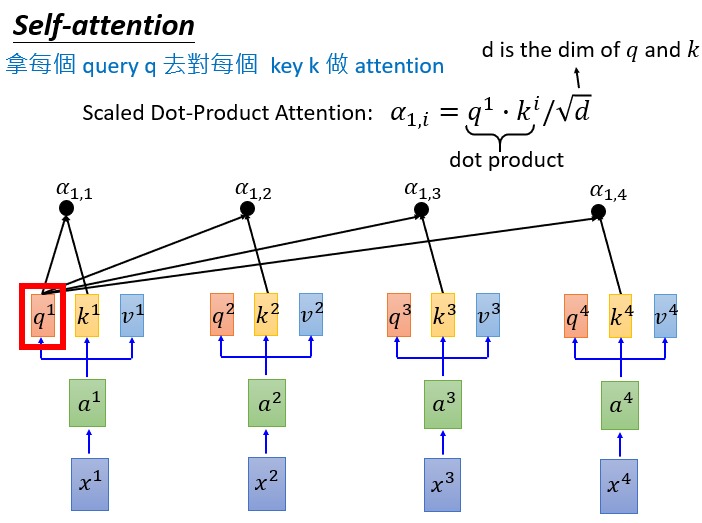
注意上图中计算权重 $\alpha$ 的时候是用 query 和 key 的內积再除以 $\sqrt{d_k}$。这个 $d$ 是向量的维度,当向量很长的时候,query 和不同的 key 的內积结果可能差异很大。除以 $\sqrt{d_k}$ 是为了让 $\alpha$ 尽可能小一些,在下一步做 softmax 的时候避免某个 key-value 对的权重很大。
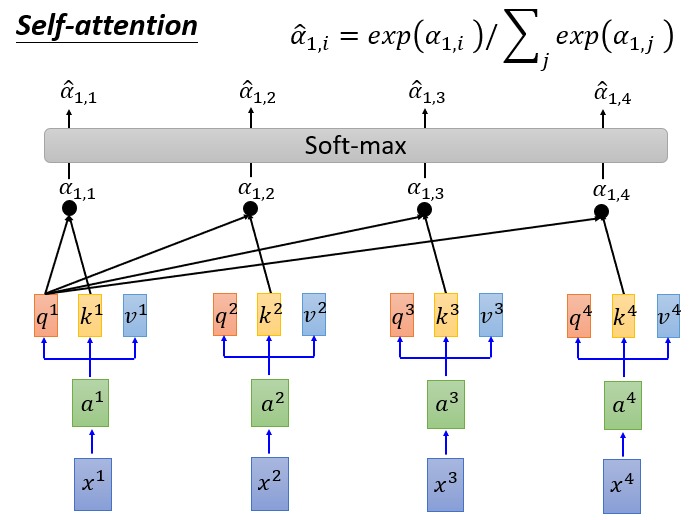
有了 softmax 之后得到权重 $\hat{\alpha}$ 然后每个输入 $x$ 就被映射为了另外一个向量 $b$:
可以对整个序列,使用矩阵运算得到 QKV:
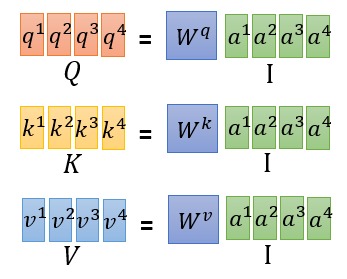
Query 对 Key 的 match 操作也可以用矩阵运算完成,得到 A 为权重,A 的各列做 softmax 就得到了最终的权重:

最终的输出依然是矩阵运算:
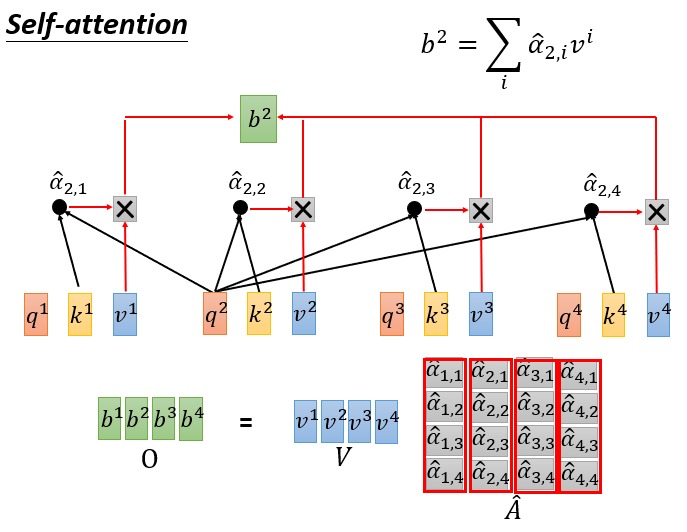
整个过程都可以使用矩阵运算完成,而 GPU 又恰恰擅长做矩阵运算。论文中把上述过程写作矩阵运算,看起来很难理解,拆开看就清晰多了。
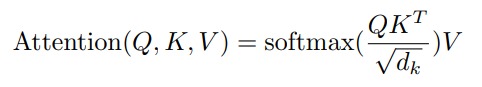
前面描述的就是 Self-Attention 的计算过程,Self-Attention 做的工作就是把输入序列映射为另外一个序列。
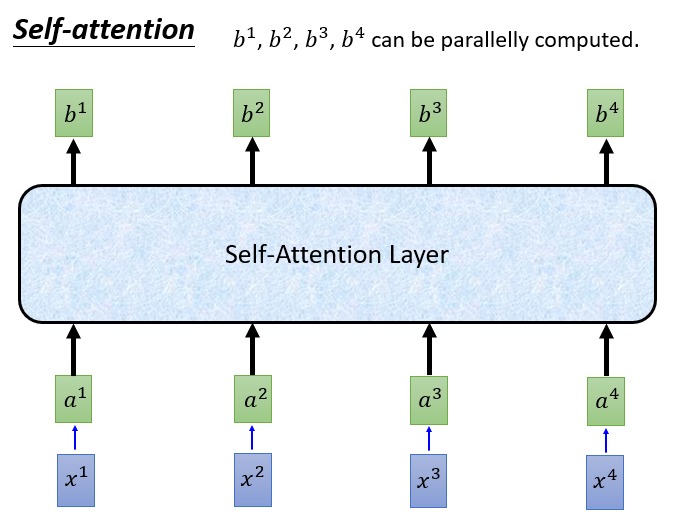
Self-Attention 中每个 token 输出的向量是所有 token 的输入向量的线性变换的加权和,可以认为每个 token 的输出考虑到了所有输入的 token 的信息。
那么什么是 Multi-head 呢?可以想象每个 token 对应一个 q, k, v,这让每个 token 关注的点比较单一,为了获得更丰富信息,可以让每个 token 有多组 q,k,v,然后每个 token 经过多个 Self-Attention 得到多个输出。这就是 Multi-Head Attention 的思想。
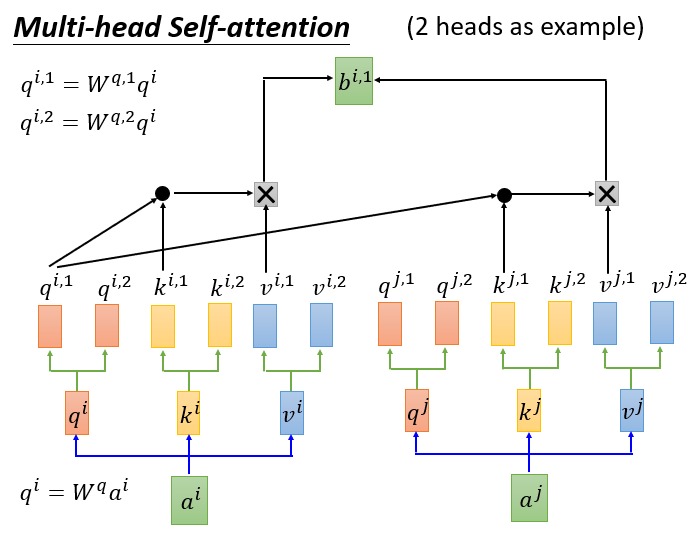
把原来的 query, key, value 乘以多个矩阵,得到多组 query, key, value 的线性变化,最后也就能得到多个输出 b。将多个输出拼接起来,经过一个 Linear 层(下图中方框部分),得到 Multi-Head Attention 最终的输出:
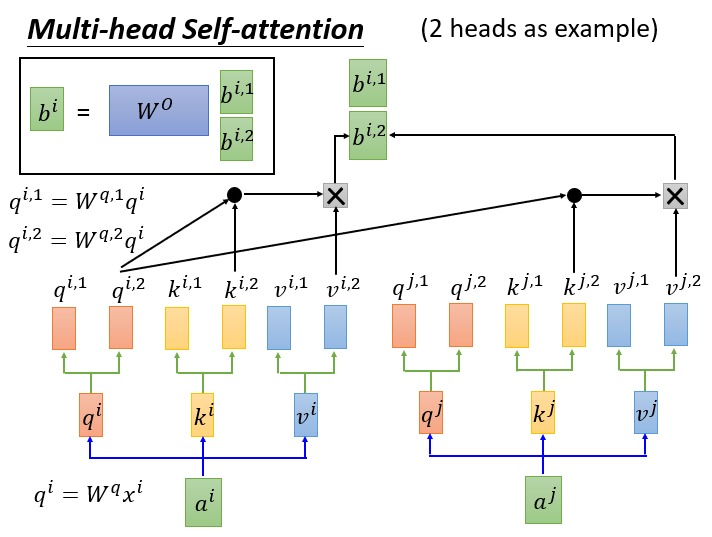
至此,再去看原论文中 Multi-Head Attention 的图就会很清楚了。
Positional Encoding
在 Self-Attention 中输入序列是没有位置信息的,在 RNN 中输入的先后可以表征位置信息,而 Self-Attention 无法表征位置信息。因此在输入的时候,就向加入位置信息。
Positional embedding 是一个稠密的向量,用来编码一个 token 在序列中的位置信息。Positional Embedding 可以学习得到,但在这篇论文中手工指定。其定义如下:

其中 $pos$ 为 token 在序列中的位置信息,$i$ 是 Embedding 的某个维度,$d_{model}$ 是 Embedding 总的维度。每个 token 的 Positional Embedding 就用上面的式子计算。这样做据说有好处,且看下面分析:

此图来自于 Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
上图上半部分,横坐标为 token 在序列中的位置,纵坐标为 Embedding 的 dim,颜色表示数值大小(-1~1之间)。可以看到每个 token 的 Positional Embedding 都不一样。观察上图中 Embedding 的第 100 和 101 维(图中红色和蓝色横线)和第 22 和 60 个 token(黑色虚线),会发现一个现象:22 和 66 两个位置的 Embedding 中的 100 和 101 维的值是完全相同的。
原论文中说,这种编码方式可以学习到相对位置信息。这是因为 cos 和 sin 是周期函数,序列中不同的 token 只要他们的间距相同,那么他们的 Embedding 中某些维度的值就相同。因此 token 之间的相对位置可以根据 Embedding 中某些维度上的值相同来确定。
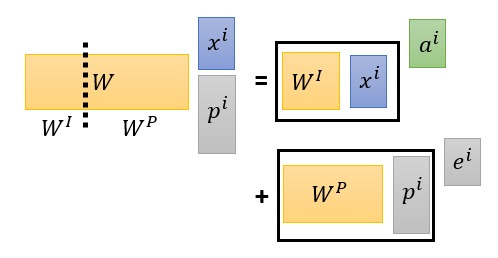
关于 Positional Embedding 的最后一个疑问,为什么 Positional 不是个输入向量拼接,而是和输入相加呢?论文中用 cos 和 sin 函数生成了 Embedding 然后和输入相加,那不是 Embedding 信息又混在输入里面了?
考虑做拼接的情况,因为输入是要做矩阵运算得到 QKV 的,但做了矩阵后,其实位置信息还是混到输入中了。看下图,把输入 $x$ 和 位置信息 $p$ 拼起来,然后做矩阵运算,相当于做分块矩阵运算,然后把各自结果加起来。
Add & Norm
对于每个 token 而言 Multi-Head Attention 输出的还是和输入相同维度的向量,Multi-Head Attention 上面的 Add & Norm 中 Add 做的就是把输入和输出加起来,就像残差网络那样。Norm 就是做 Layer Normalization。
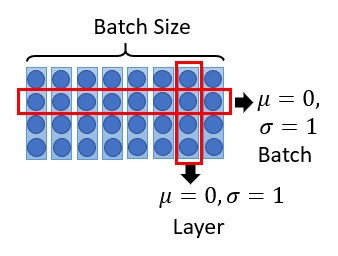
如上图所示 Batch Normalization 是对一个 batch 的输入中的同一维度做 Normalization,而 layer Normalization 是对每个输入做 Normalization。
Feed Forward
看 Transformer 的结构图,经过 Add & Norm 之后经过了一个 Feed Forward Netword 这就是一个两层的全连接网络,中间层使用 ReLU 激活函数,输出不用激活函数,然后再次做 Add & Norm 得到的结果。
前面的 Self-Attention 部分,输入向量的不同维度之间没有进行过交互,这里的全连接网络就是让不同维度之间可以进行组合。
Decoder
观察 decoder 部分,它和 encoder 的唯一不同就是多了 Masked Multi-Head Attention 部分。Encoder 可以把输入序列一次性全部编码完成,但是 Decoder 必须要一个一个地解码。
Decoder 的输入也是个序列,但在解码过程中序列是不完全的,即只有一家解码出来的部分。这里 Masked 就是把尚未解码的部分屏蔽掉,即在计算 Attention 的时候让未解码出的部分权重为 0。Masked Multi-Head Attention 的输出作为 Query 输入到下一个 Multi-Head Attention 中,此 Multi-Head Attention 的 Key-Value 则来此 Encoder。
Decoder 也会重复方框中的部分很多次,这里称这个框中的部分为 block,encoder 的编码结果会输入给每一个 block。第一个 block 的输入可能就是表示序列开始的 token <BOS>,接下来的 block 的输入就是前一个 block 的输出。
最后一个 block 的输出输入给一个线性分类器,做多分类任务来预测解码结果。
至此,Transformer 中的各个部分都已经说清楚了。
总结
在 Transformer 之前,Encoder-Decoder 模型基本组成就是 RNN 加 Attention,这篇论文使用 Self-Attention 完全取代了 RNN,相比于 RNN,Transformer 的并行程度更好,可以有效利用先进的硬件资源 GPU。由于 Self-Attention 不能提供位置信息,可以在输入阶段自家表示位置的编码信息。
如今 Transformer 在 NLP 领域已经无处不在了,很多重型武器,如 BERT、GPT-2, 都基于 Transformer,各种任务的 base line 也被基于 Transformer 的模型大幅刷新。而我才刚刚理解 Transformer,我快学不动了。
推荐阅读
如果你希望使用代码实现 Transformer,那么建议阅读 Aurélien Géron 编写的 Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow 的第 16 章,作者用 Keras 实现了 Transformer。
强烈建议看李宏毅老师讲 Transformer 的课程视频,链接在此。李宏毅老师讲的很清晰,我这篇文章中大量借用了李宏毅老师 PPT 中的图,感谢他。