机器学习 - 简介
我接触机器学习有一年多了,在学习过程中一直独自探索,走了不少弯路。比如,在网上查如何学习机器学习,别人会推荐你去看南京大学周志华老师的《机器学习》,李航博士的《统计学习方法》。但我相信大部分人在如何去读这些书,一定会遭受挫折,进而可能对机器学习敬而远之。因为在缺少必要的背景知识的情况时,去读这些偏重理论的书,是不会成功的。
有人认为机器学习很注重数学,应该先去把数学学好。其实错了,在入门阶段,大部分机器学习算法只需要有高中数学+忘得差不多的高等数学有足够了。我们应该去实践这些算法,用这些算法去解决某个问题,在实践中去感受各种算法,然后在去详细地了解原理,而不是一开始就埋头于理论中。
学习机器学习和其他编程知识类似,你依然需要从代码入手,先跑一跑简短的例子,然后再试图搞明白其中的原理,这个时候你可以去查阅前面提到的书籍。看书 1 小时,就应该实践 10 小时,机器学习也是如此。本系列文章准备通俗(可能不严谨)地讲解常见的机器学习算法,并给出一些直观的解释。很多涉及推导的算法,我做不到比相关书籍讲的还好,在某些地方也会推荐看相关公开课,和相关书籍。每个知识点,会附加一些实际的例子,通过例子可能切实地观察到机器学习算法运行的过程和结果,加强对各个知识点的理解。对需要补充学习的知识点,我会给出我认为最好的参考资料,以及学习建议。
李宏毅老师的机器学习课程 讲的很好,老师给出了大量的例子,已经直观的比喻,我认为可以从这门课程入手学习必要的理论。在学习过程中千万不要试图在短时间内穷尽所有的算法,应该一个一个来,在学习了理论之后,尝试使用该算法,然后再自行推导该算法,如此反复多次地使用算法。
费曼先生说过 “If you want to master something, teach it.”,本系列文章更多是帮助自己梳理机器学习中的各种知识点。同时我希望他能对别人也有用。
机器学习的整个脉络
下图中总结了机器学习算法的大体分类:
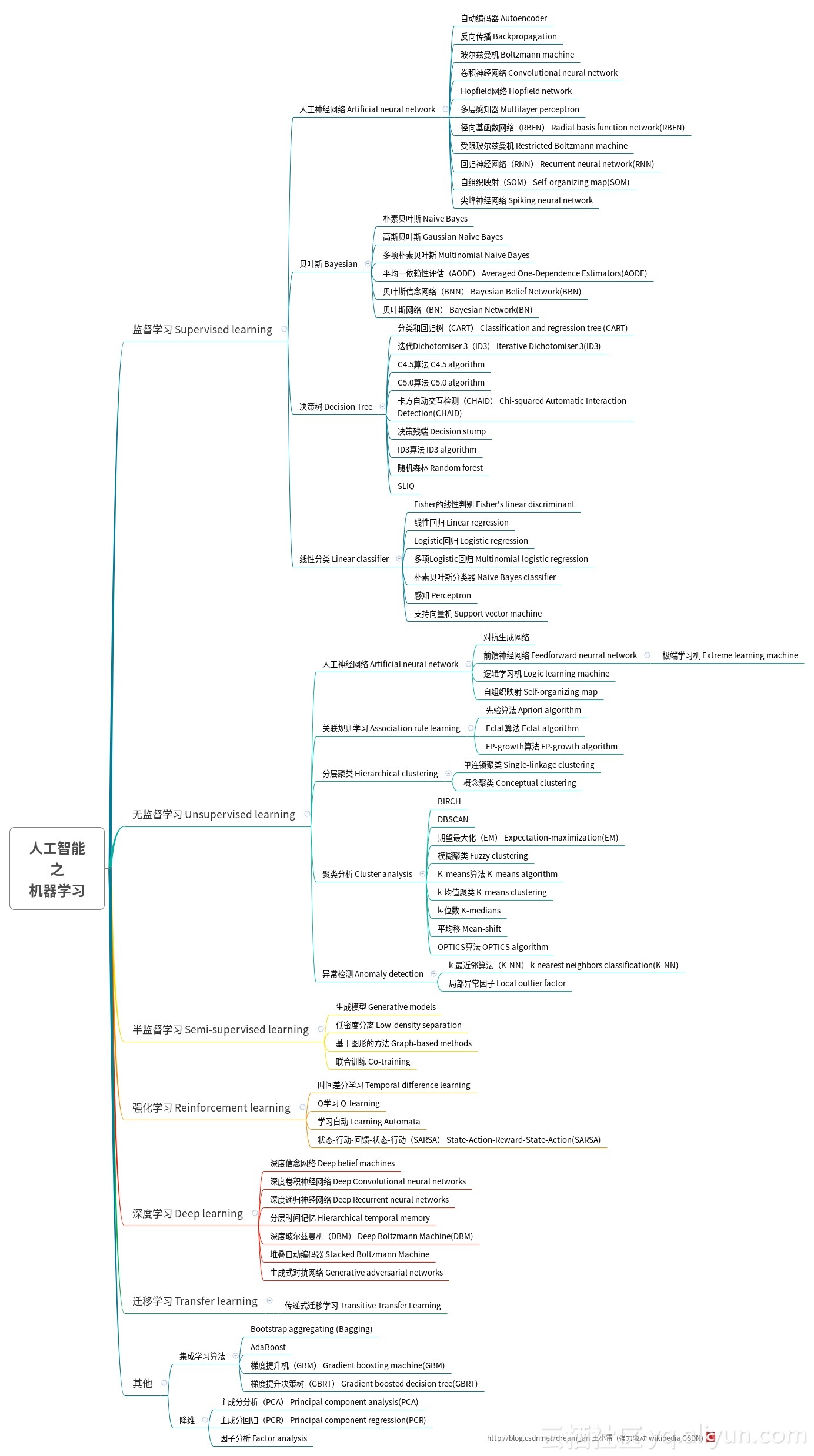
图片来源见水印,感谢原图作者。
要想运用机器机器学习算法解决某个问题,单了解了机器学习算法是远远不够的,还需要了解数据处理的方法,掌握常见工具的使用。再后面的一系列文章中,我们用到具体的工具时,我会给出一些建议的资料。
这里我想先对机器学习中的一些名词和基本概率做一下解释,万一真的有小白来看这些教程呢?
什么是机器学习
在学习具体的机器算法之前,需要大致知道机器学习是什么?机器学习是一系列方法,用于从数据中寻找规律,自动发掘出数据中某些特征之间的关系,进而给出有用的预测。下面举个例子:

一个邮件过滤程序,需要能够分辨出邮件是否为垃圾邮件。要想分辨出垃圾邮件,传统的编程方法可能是为垃圾邮件制定一系列的规则,比如包含 “促销”、”抢购” 等词的邮件视为垃圾邮件。但这需要大量的规则,而且还会出现误判。
如果使用机器学习,解决这一问题的方法是:给机器学习算法一大堆邮件,并告诉它那些是垃圾邮件,那些是正常邮件,然后让算法自动地寻找垃圾邮件和正常邮件的特征。学习完成后,该机器学习算法就会知道垃圾邮件有什么特征,下一次遇到一封新的邮件,此程序就能对该邮件分类。
机器学习就是让机器去从数据中学习,至于如何学习,这就是研究机器学习算法的人要考虑的事情了。我们学习机器学习,就是要学会那些能让机器进行自动学习的方法。然后将这些方法用代码实现,而后机器就可以自动地学习了。
机器学习算法的分类
机器学习算法从不同的角度可以分为很多的类别,但这里,我不愿把问题弄的太复杂,只描述最常见的分类
人类每天都在学习,我们通过看书、听课、做练习来进行学习,我们从书本、老师那里学习。机器学习算法是让机器进行学习的一系列方法,我们人类从书中学习,机器从数据中学习,人通过看书来学习,机器通过机器学习算法来学习。机器学习算法就是机器进行学习的策略。
在垃圾分类的场景下,机器从大量的邮件中来学习,每个邮件有具体的内容,以及邮件对应的类别(是否为垃圾邮件)。在机器学习中,我们把邮件内容经过处理得到邮件的特征(feature),特征用 $x$ 表示,邮件的类别我们称为标签(label),标签使用 $y$ 来表示。
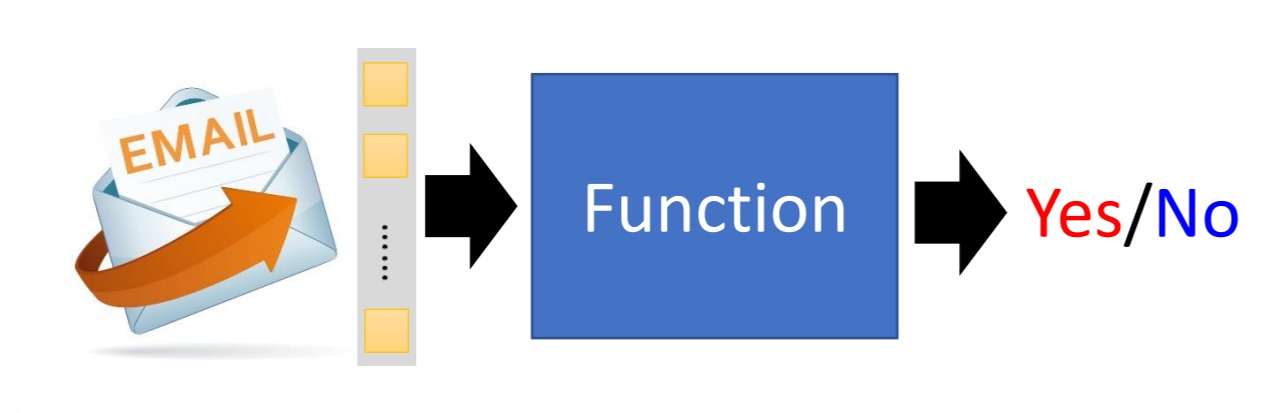
机器学习算法就相当于一个函数,把邮件的特征输入进入,函数返回分类的结果。那么这个函数的定义是怎样的呢,函数的定义就是机器要使用机器学习算法来学习的目标。有了这个函数,新的邮件输入进来就可以判断它是否为垃圾邮件了。
监督学习(supervised learning)
每个邮件的特征是多个维度的,比如发件人信息、文本内容、是否包含图片等等,在机器学习中,我们把参与训练的数据中最小单元成为样本。
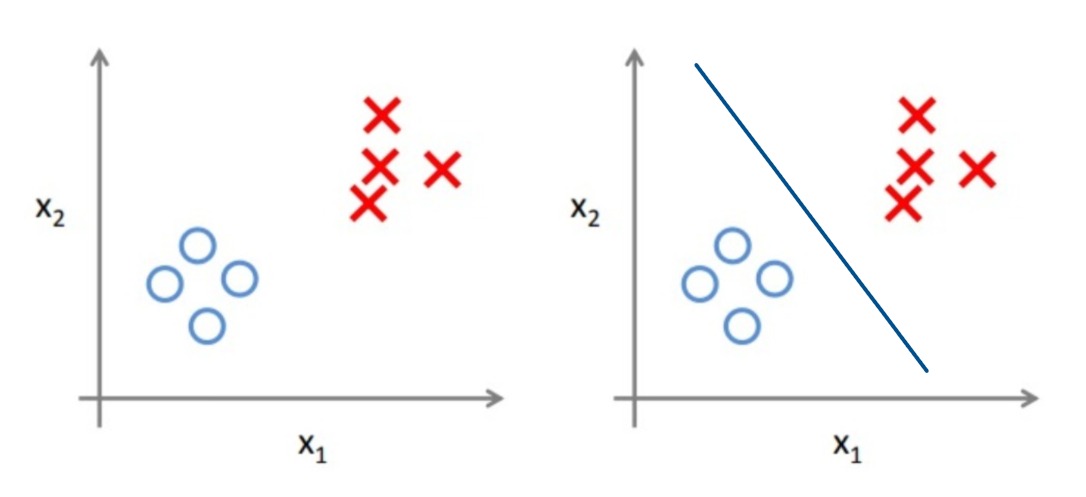
假设这里的样本包含两个维度的特征,每个样本都对应在二维平面上的一个点,图中 O 和 X 是样本的标签。要想区分两类样本,机器学习算法可能会寻找到一条分界线,在平面上将两类样本完全分开。
只有样本有对应的标签时,我们才能画出这条分界线。这类使用有标签的数据进行学习的算法被成为监督学习。监督学习给定了输入 $X$ 和 输出 $y$,然后去学习由 $X \to y$ 的映射函数 $f$。
非监督学习(unsupervised learning)
监督学习需要样本有标签,而标签往往时不易获得的,常常需要人工去进行标注。现实生活中有的往往是没有标签的样本。
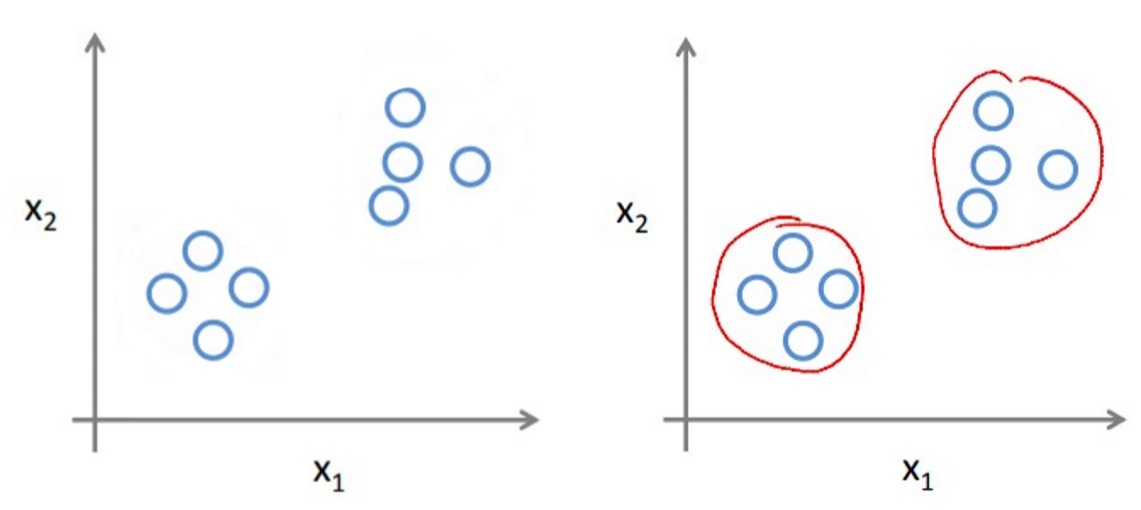
对于没有标签的样本,机器学习算法可以通过分析整个样本集,发现其内在的规律。比如上图中的例子,样本并没有标签,但是它们明显聚成了两个簇。如果一个任务是对样本进行归类,那么不需要标签也可以做到。这类通过挖掘数据分布,而不依赖标签的学习方法被称为非监督学习。常见的聚类算法就是非监督学习。
半监督学习(semisupervised learning)

有大量无标签的样本,和少量有标签的样本。采用非监督学习可以对无标签样本进行聚类,利用落在各个类别中的少量有标签样本,能够确定各个类别的某些特征。比如相册应用,可以将一个人的不同照片聚类,一旦其中的某张照片被用户标记为某个人,那么类别中所有照片就都被标记了。
总结
本文交代了这一系列教程的用意,并对机器学习的个别概念进行了解释,这些内容对于熟悉的人而言没有任何价值,对不懂机器学习的人而言又显得太少。因此,推荐一些阅读材料供入门者食用。
推荐阅读
读完了上面的内容,你一定还是不知道什么是机器学习,这很正常。这里推荐台湾大学李宏毅老师的机器学习课程,你可以看一下第一讲。第一讲中举了大量的例子来描述什么是机器学习,相信看完之后你对机器学习的整体会有较清晰的认识。