链接与装载相关知识
静态链接
静态链接把所以依赖的模块打包成一个可执行文件,依赖的模块升级之后,无论 ABI 有没有改变,都需要重新链接。而且如果系统中存在很多个进程的可执行文件都是静态链接的,那么就会存在大量的空间浪费。
动态链接
要解决空间浪费和更新困难的问题,可以把程序的模块分开,形成独立的文件。等到程序运行的时候,在进行加载。把链接过程推迟到运行时再进行,这就是动态链接的基本思路。
动态链接器会被映射到进程的地址空间中,在系统开始运行之前,首先会把控制权交给动态链接器。
地址无关代码
共享对象在装载时,如何确定它在进场虚拟空间中的位置呢?
装载时重定位
在链接时,对所有的绝对地址的引用不做重定位,把这一步推迟到装载时完成。模块的装载地址确定后,对程序中所有的绝对地址进行重定位。比如模块 A 装载在位置 0x10000000,模块 A 中的函数 foo 的偏移量为 0x100,这样 foo 的地址就时 0x10000100。
假如 B 模块使用了 foo 函数,在 A 模块装入之后,foo 的地址就确定了,B 模块装入后,需要修改对 foo 的引用地址为 foo 的绝对地址。这自然需要修改 B 模块所在的地址空间,那么模块就没办法在多个进场中共享了。动态库中的代码部分在多个进场中共享,因此不能修改,但是数据部分在多个模块中均有拷贝,可以使用装载时重定向的方法。
地址无关代码(PIC,Position Independent Code)
装载时重定位可以处理动态模块中的绝对引用,但是由于指令部分被修改了,指令无法在多个进场中共享,这就失去了动态链接的意义。有一部分指令引用的是模块内部的数据和函数,这可以使用相对寻址来解决。如果我们可以把哪些指令中需要被修改的部分,和数据部分放在一起,这样指令部分可以保持不变,而数据部分每个进程各有一份副本。
把模块中的地址引用按照是否跨模块分为两类,每一类又可以分为指令引用和数据引用,共四种情况如下:
- 模块内部的函数调用
- 模块内部的数据访问
- 模块外部的函数调用
- 模块外部的数据访问
static int a;
extern int b;
extern void ext();
void bar(){
a = 1; // 类型 2
b = 2; // 类型 4
}
void foo(){
bar(); // 类型 1
ext(); // 类型 3
}
类型 1:模块内部调用或跳转
调用当前模块的函数,当前指令和函数入口的偏移量在编译的时候是已知的,因此使用相对地址调用即可。
类型 2:模块内部数据的访问
当前指令和数据的偏移量已知,使用当前指令的地址加上偏移量就可以得到数据的绝对地址。这需要得到当前的 PC 值,但是数据访问没有相对于 PC 进行寻址的方式。但有办法间接地获取到当前指令的地址,在调用函数(call)的时候会将下一条指令 push 到栈顶部,只需要在调用的函数中取得栈顶中存的值,就可以得到下一条指令的地址了。
类型 3:模块间函数调用
考虑下面的代码,其中使用了 printf 函数,这是 C 语言运行库中的函数。如果使用动态链接,那么在链接的时候,程序是不知道 printf 函数的地址的,因为模块在动态加载时加载的位置是目前不确定的,链接的时候只知道存在 printf 这个函数。
int main(int argc, char* argv[]){
const char *hello = "hello ";
fwrite(hello, 1, strlen(hello), stdout);
printf("world!\n");
}
做法是在链接的时候生成一个辅助函数,这个函数会去一个固定的位置读取 printf 的地址,然后调用 printf 函数。即,在链接时给 printf 留下一个坑,在模块加载进来时,在这个坑上填写 printf 的真实地址,这个坑的位置在链接的时候就确定了。
.text
call printf_stub
printf_stub:
mov rax, (printf_position:)
jmp rax # 调用 printf 函数
.data
printf_position:
printf 函数的实际位置 # 这里的值在加载的时候填写
存放 printf 地址的表叫做重局偏移表(GOT, Global Offset Table),辅助函数 printf_stub 放置的地址也有一个名称,叫做程序链接表(PLT,Procedure Link Table)。
可以实际测试一把:
$ g++ -fPIC main.cpp
查看一下段信息:
$ objdump -h a.out
a.out: file format Mach-O 64-bit x86-64
Sections:
Idx Name Size VMA Type
0 __text 00000034 0000000100000f40 TEXT
1 __stubs 0000000c 0000000100000f74 TEXT
2 __stub_helper 00000024 0000000100000f80 TEXT
3 __cstring 0000000e 0000000100000fa4 DATA
4 __unwind_info 00000048 0000000100000fb4 DATA
5 __got 00000010 0000000100001000 DATA
6 __la_symbol_ptr 00000010 0000000100002000 DATA
7 __data 00000008 0000000100002010 DATA
可以看到存在 got 和 stubs 两个段,因为我这里是在 Mac 上测试的,所以没有看到 PLT 段,但是如果在 Linux 上测试就能看到,不过两个平台上思路是相近的。
类型 4:模块间数据访问
访问一个其他模块中定义的变量,由于其他模块装载的位置不确定,该变量的位置自然也不确定了。因此在链接的时候,能够通过符号知道某个符号是在哪个模块中,但是不知道这个符号的具体位置。
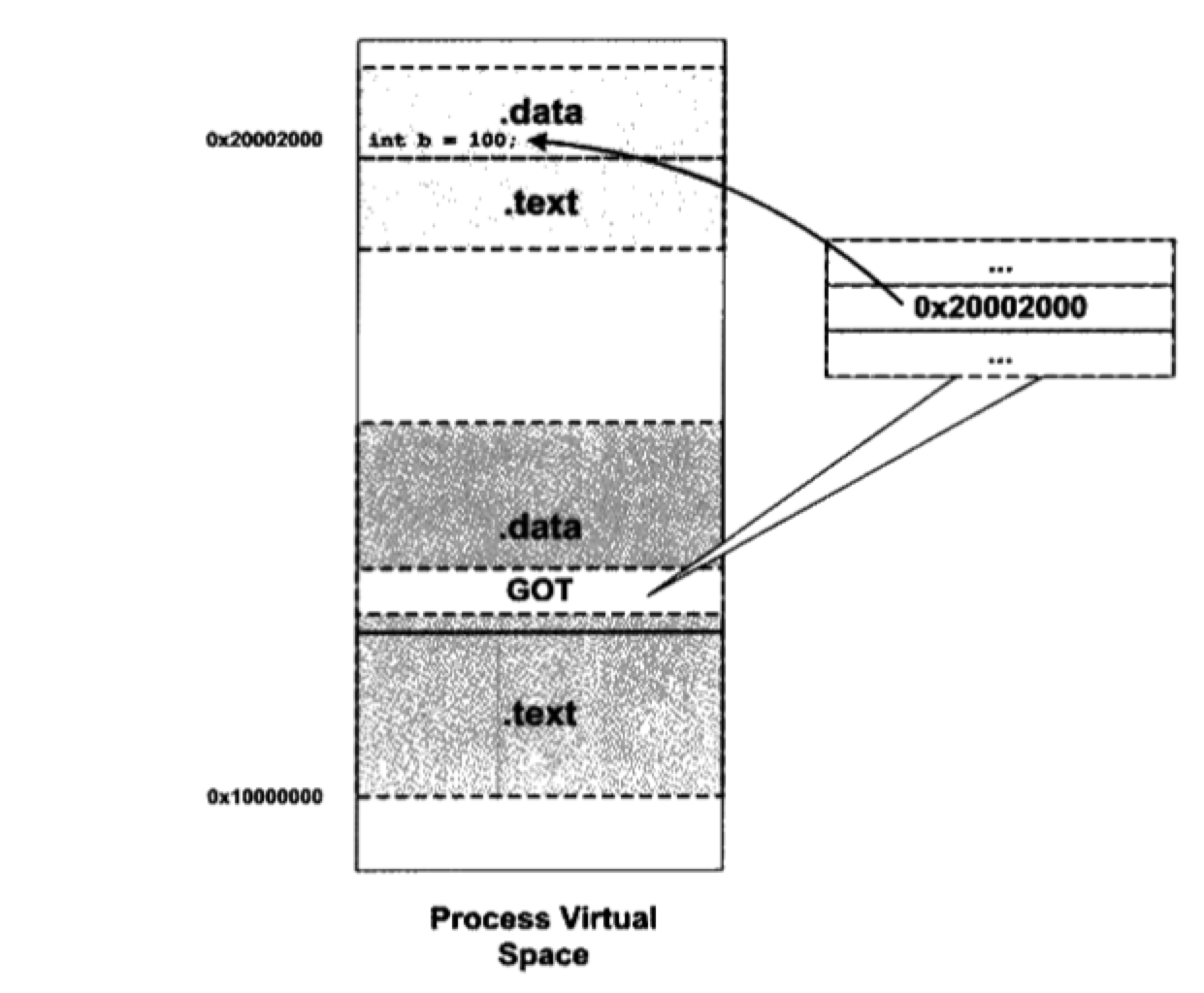
模块中有一个 GOT(Global Offert Table),这个表用来记录全局变量和和函数的实际位置。模块被装载进来后,装载器会根据模块被加载的位置和模块中各个数据的偏移,计算出绝对位置,然后填到这个表里面,GOT 在链接的时候就预留好了。各个模块加载进来之后只需要把自己的暴露出来的函数和数据填入表中即可。
其他模块在用到该模块的变量和函数时,只需要从 GOT 中查找即可。比如,上图中 .data 段有变量 b,当指令中需要访问变量 b 的时候,会先找到 GOT,并找到 b 对应的地址。可以认为 GOT 中存放的是各个变量的位置的位置,即指针的指针。
动态链接的程序的运行过程
进程加载后,将控制权交给程序的入口,程序的入口中把控制权交给动态链接器,动态链接器加载所有的动态库,然后把环境变量,主函数的参数等信息放到堆栈上,然后把控制权交到 main。
运行时链接
使用以下函数,可以在运行时打开某个动态链接库,然后从中导入某个符号。
void * dlopen(const char * __path, int __mode);
int dlclose(void * __handle);
void * dlsym(void * __handle, const char * __symbol);
char * dlerror(void);
线程局部存储
使用如下语法创建线程局部存储:
__thread int num; // C
thread_local int num; // C++
在虚拟存储空间中有一个 .tdata 段,其中存放了全部的线程局部存储的变量,每个线程都会有一份自己的拷贝。在创建线程的时候(调用 clone)可以不共享 .tdata 段,而其他段都共享,这样各个线程就有了自己独享的存储了。
函数调用过程
int foo(){
int a = bar(1, 2, 3);
return a;
}
push %ebp # 先把 ebp 压入栈中
mov %esp, %ebp # 把当前的 esp 作为新的 ebp
sub $16, %esp # 为当前栈帧开辟空间
mov $1, (%rsp) # 初始化参数 1 2 3,这里的 1 2 3 其实是存储于调用者的栈帧里面的
mov $2, 4(%rsp)
mov $3, 8(%rsp)
call foo # 调用函数
mov %eax, -4(%ebp) # 返回值
add $16, %esp # 消除当前栈
pop %ebp # 取出旧的 ebp 赋予 ebp
ret # 退出函数调用,从栈顶 pop 出 ip,然后跳转
系统调用
Linux 系统中系统调用是使用 0x80 中断完成的,各个通用寄存器用于传递参数,eax 寄存器用于表示系统调用的编号,每个系统调用都用唯一的编号。
软件或者硬件通过中断发出请求,要求终止当前的工作转而去处理更加重要的事情。比如用户按下键盘上的某个按键,键盘的驱动程序就会产生一个中断,让操作系统来读取输入的内容。每一个中断都有一个唯一的编号,在操作系统中有一个中断向量表,其中保存了每个中断对应的处理函数。
下图中为调用 fork 的流程:
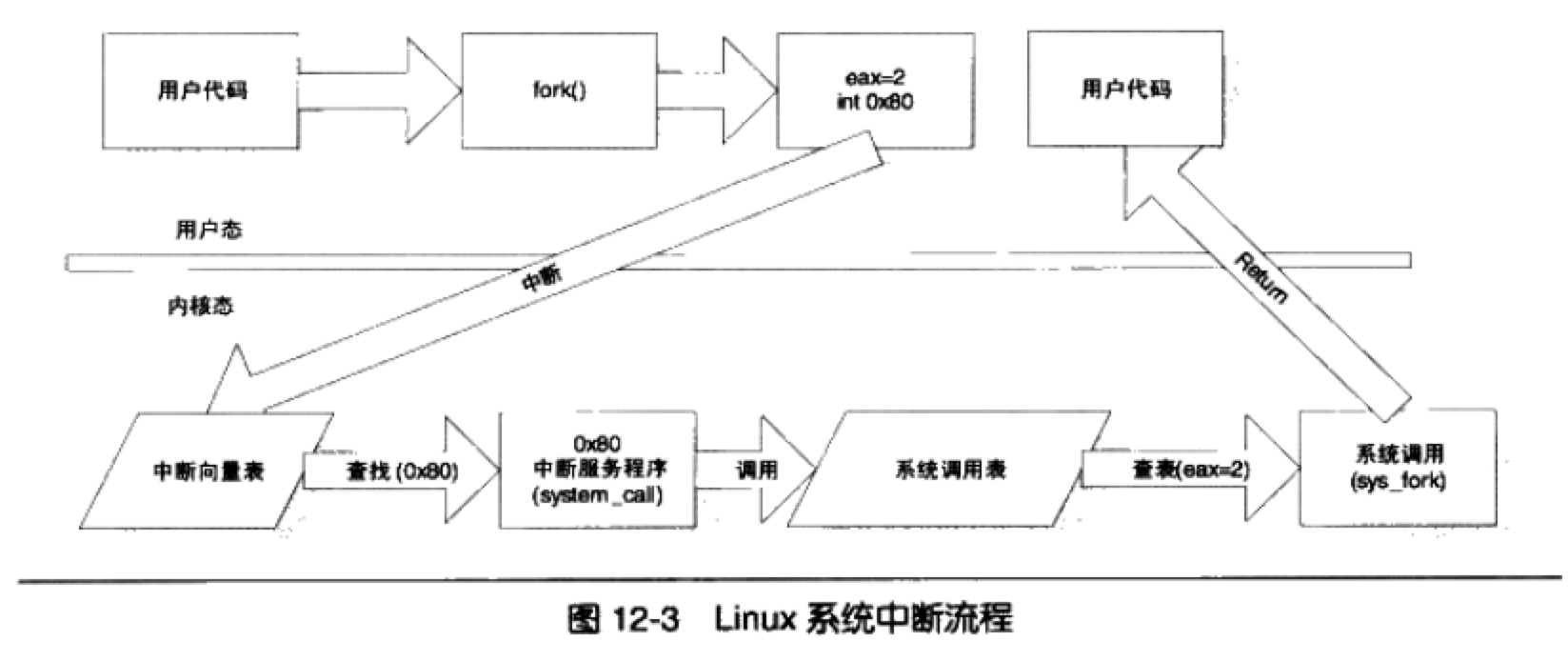
用户调用 fork,设置 eax=2,使用 int 0x80 指令产生系统中断,系统调用 0x80 中断的中断处理函数,此处理函数再更具 eax 的值,找到对应的系统调用 sys_fork 然后调用该函数,调用完成后返回用户态。
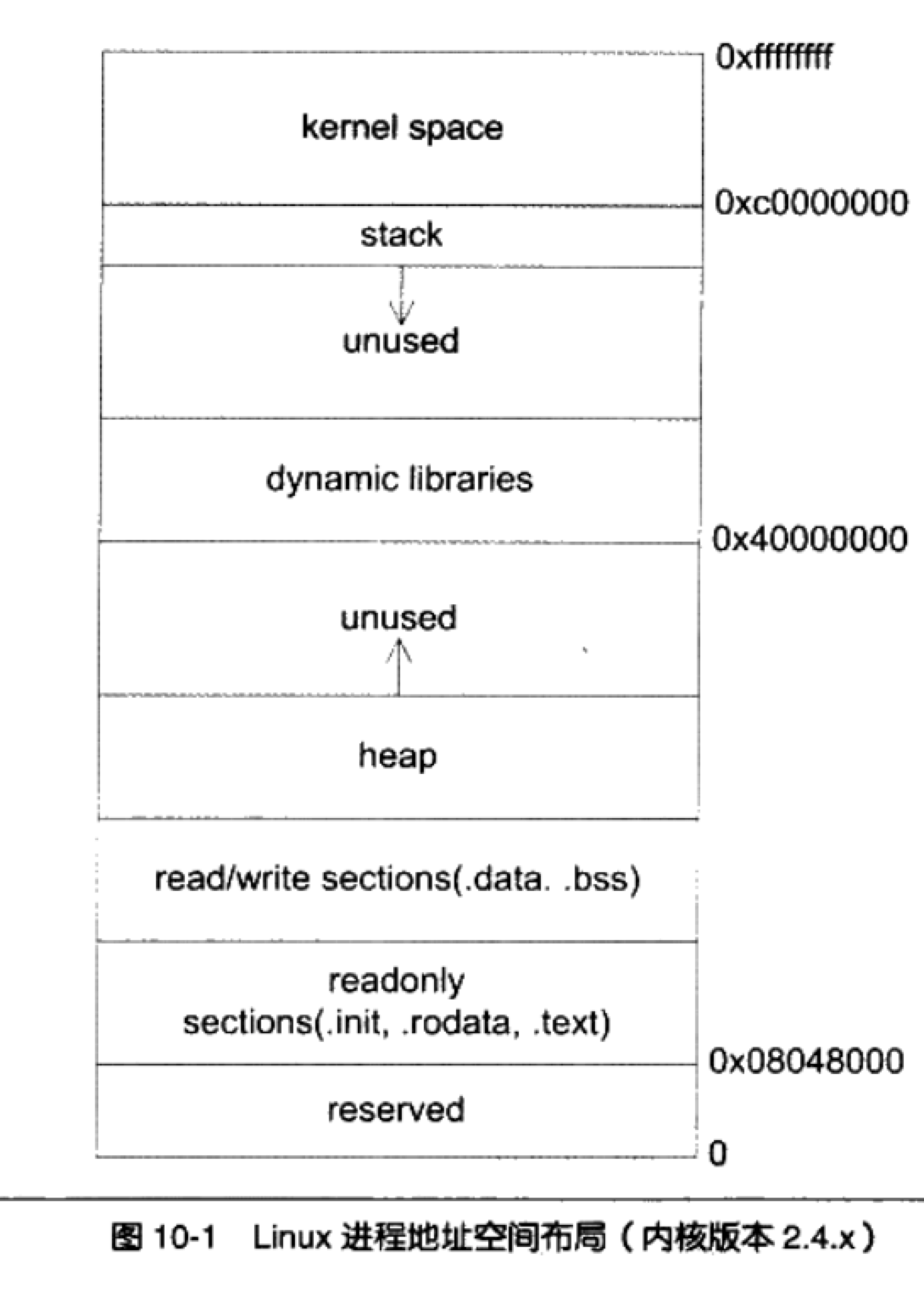
内存布局
Linux 下一个进程里典型的内存布局:
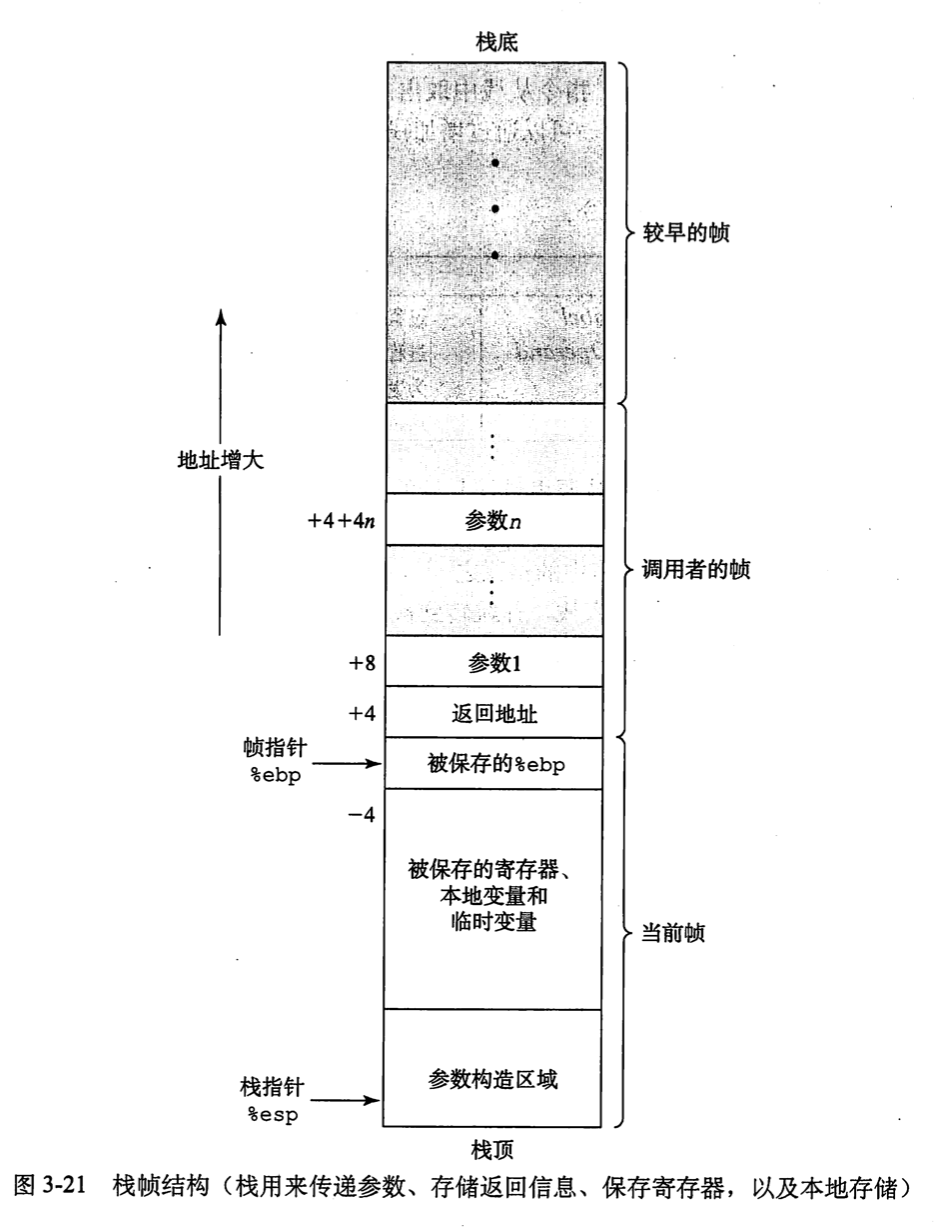
栈与函数调用
int foo(){
int a = bar(1, 2, 3);
return a;
}
这个函数的调用过程大致如下:
- foo 在调用函数 bar 之前先把参数压入栈顶
- 然后使用 call 指令调用 bar 函数,call 指令会把下一条指令的地址压入栈中,然后跳转到 bar 函数的入口。
- bar 立刻保存前一个帧的帧指针,然后做把当前栈顶指针设置为新的帧指针,然后减小栈顶指针 esp,开辟帧空间。
- 计算完成后,再增大栈顶指针,消除帧空间。
- 恢复原来的帧指针 ebp,然后使用 ret 指令跳转到 call 的下一条指令的位置。
下面是 foo 函数的汇报代码:
push %ebp # 先把 ebp 压入栈中
mov %esp, %ebp # 把当前的 esp 作为新的 ebp
sub $16, %esp # 为当前栈帧开辟空间
mov $1, (%rsp) # 初始化参数 1 2 3,这里的 1 2 3 其实是存储于调用者的栈帧里面的
mov $2, 4(%rsp)
mov $3, 8(%rsp)
call foo # 调用函数
mov %eax, -4(%ebp) # 返回值
add $16, %esp # 消除当前栈
pop %ebp # 取出旧的 ebp 赋予 ebp
ret # 退出函数调用,从栈顶 pop 出 ip,然后跳转
内存管理
操作系统管理这堆内存,它提供了系统调用,可以申请一块内存。但是频繁第向操作系统申请内存,会带来较大的开销。为此,通常是程序的运行库向操作系统申请大块的空间,然后自己管理。相当于向操作系统批发了一大块内存,然后自己来零售给应用程序。
brk 的作用是把 data 段的边界扩大,如此,在 data 段中就有可以使用的空间了。
void* brk(const void *); // 设定 data 段的上边界,但是通常并不知道 data 段原本的上边界在哪里
void* sbrk(int offset); // 把目前 data 段的上边界扩大 offset,然后翻
mmap 用来把文件映射到内存中,并返回该内存。但是也可以选择不映射文件,这样就只是返回一块内存空间。munmap 可以用来释放映射的空间。
#include <sys/mman.h>
#include <unistd.h>
#include <sys/fcntl.h>
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
int main(){
int fd = open("./test.txt", O_RDWR, S_IRUSR | S_IWUSR);
struct stat st;
if(fstat(fd, &st) == -1){
perror("couldn't get file size");
}
printf("file size is: %ld\n", (long)st.st_size);
char *ptr = mmap(NULL, st.st_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
for(int i = 0;i < st.st_size; i++){
putchar(ptr[i]);
}
munmap(ptr, st.st_size);
close(fd);
}
void *malloc(size_t n){
void *ret = mmap(0, n, PROT_READ|PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
if(ret == MAP_FAILED){
return 0;
}
return ret;
}