进程相关的知识
什么是进程
进程是执行中的程序的抽象。程序是一个文件,这个程序中的指令被操作系统加载到内存,然后执行起来,如此就得到了一个进程。
进程的创建
fork
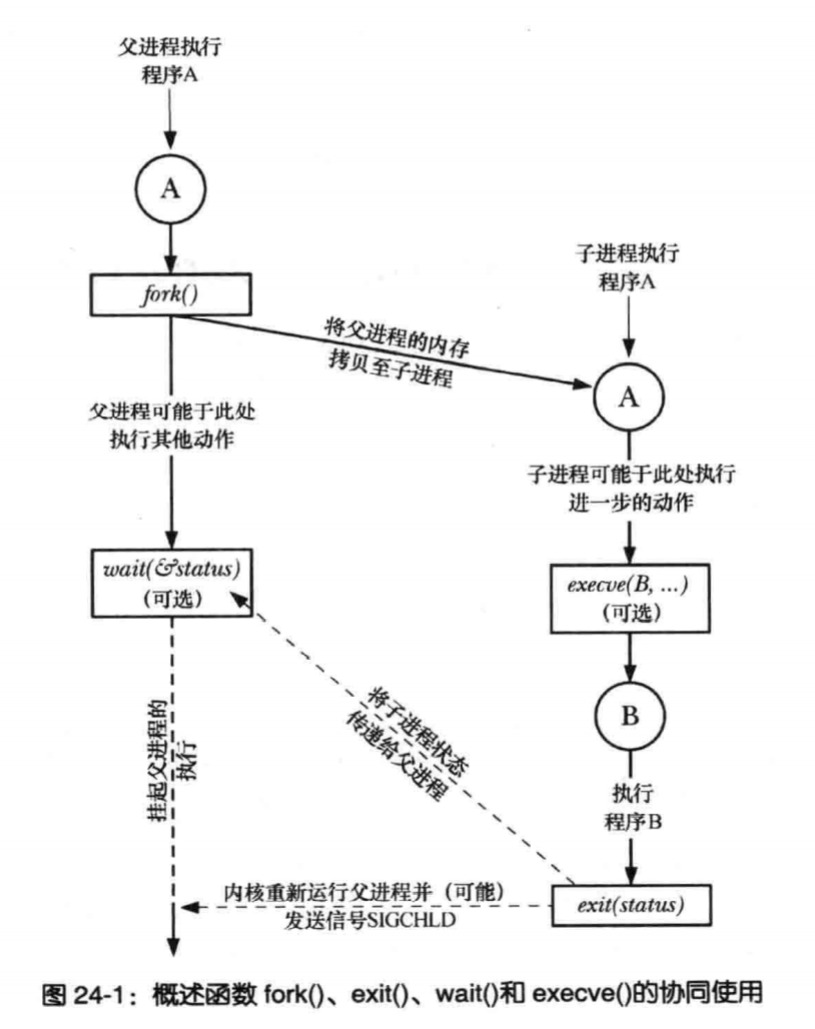
fork 用于创建进程,当某个进程调用 fork 后,一个新的进程就产生了,这个进程被成为子进程,创建该子进程的那个进程就是父进程。子进程和父进程共享代码段,数据段、栈和堆采用写时复制。调用 fork 之后在父进程和子进程中返回值不同,因此可以根据返回值来判断,当前是在子进程还是父进程中。
pid_t pid = fork();
switch(pid){
case -1:
// handle error
case 0:
// child
default:
// parent
}
- 共享代码段
- 数据段、堆和栈采用写时复制。
fork 调用后是先执行父进程还是子进程是不确定的。假如总是先执行父进程,但是有可能在执行开始前,父进程的时间片用完了。
因为很多子进程在创建后都会调用 exec 来执行一个程序,如果 fork 后先执行父进程,那么父进程的执行将导致子进程中共享的内存需要进行拷贝。而如果先执行子进程,那么 fork 后立刻执行 exec,这就不需要进行拷贝了。但从历史上看,linux 采用的策略发生过几次改变。综上,在需要依赖执行顺序的场景下,不能对系统的执行顺序做任何假设。
wait
一个进程终止后,会留下一些信息,比如退出状态。操作系统会保留这些信息,因为将来父进程可能需要获取这些信息。获取这些信息的方法是调用 wait 函数。在调用 wait 时有以下几种情况:
- 子进程尚未终止:此时 wait 将阻塞直到子进程终止
- 子进程已经终止:此时 wait 可以立刻返回,获取到子进程的退出状态
wait 返回一个已经终止的子进程的 pid,并用 status 传回子进程终止时的状态。当调用 wait 的时候,没有子进程终止,那么 wait 会一直阻塞直到某个子进程终止。调用 wait 时,如果存在已经终止的子进程,wait 会立刻返回。如果不存在任何尚未终止的子进程,wait 会出错,返回 -1,且设置 erron 为 ECHILD。
因此,可以使用下面的代码来等待所有子进程终止:
int status;
while((pid = wait(&status)) != -1)
continue;
if(errno != ECHILD)
err_exit("wait");
waitpid 和 wait 的功能类似,但是比 wait 功能要强。waitpid 可以明确等待某个特定的子进程,还可以提供参数来设置非阻塞地进行 wait。
pid_t waitpid(pid_t pid, int *stat_loc, int options);
孤儿进程和僵尸进程
如果父进程先于子进程终止,子进程成为孤儿进程,他们会被 init 进程接管。
子进程终止后,如果父进程尚未使用 wait 等函数来获取子进程的状态,那么操作系统会始终保留这些进程的状态,子进程占用的部分资源不会被释放,这些子进程成为僵尸进程。如果父进程不断地创建子进程,但是不回收,会因存在太多的僵尸进程导致无法再创建新的进程。
SIGCHID 信号
父进程要回收子进程,可以采用下列方法:
- 阻塞在 wait 调用上
- 使用非阻塞的 wait 调用,然后周期性轮询
这两种方法,主进程都难以做其他的事情。注意到子进程终止时会给父进程发送 SIGCHILD 信号,因此父进程可以监听此信号,然后在信号处理函数中回收子进程。
void child_handler(int signo){
int saved_error = errno;
// 非阻塞地调用,id 设置为 -1 表示可以回收任意可以回收的子进程
while (waitpid(-1, nullptr, WNOHANG) > 0)
continue;
errno = saved_error;
}
因为在处理信号时,可能有其他子进程也终止了,并发来了信号,但是因为该信号正在被处理,所以该信号处理函数不会被再次调用(这涉及到信号是否排队)。因此需要在这里多次调用 waitpid,但是为了避免阻塞在这里,因此需要非阻塞地调用。
进程的终止
exit 是 C 运行时库中提供的函数,而 _exit 是系统调用。exit 比 _exit 做的工作要多,具体如下:
void exit(int status){
// 1. 调用退出处理函数(使用 atexit 和 on_exit 注册的函数),执行顺序与注册顺序相反
// 2. 刷新 stdio 流缓冲区
// 3. _exit(status)
}
运行一个可执行文件
系统中正在运行的任何一个进程都是通过 fork 得来的,但是系统中的各个进程又互不相同,这是因为很多进程在创建后,立刻就使用 exec 系列函数来执行一个新的程序,该程序的内容会覆盖掉原进程空间,然后一个全新的进程就诞生了。
execve 的功能是加载一个新程序,路径为 pathname,参数为 argv,环境变量为 envp。调用此函数,将丢弃现有程序的文本段,并重新创建执行栈、数据段和堆。
exec 存在一系列的函数,其功能大致相同,只是调用方式不同,它们的函数定义如下:
int execle (const char *__path, const char *__arg, ...)
int execlp (const char *__file, const char *__arg, ...)
int execvp (const char *__file, char *const __argv[])
int execv (const char *__path, char *const __argv[])
int execl (const char *__path, const char *__arg, ...)
int execve (const char *__path, char *const __argv[], char *const __envp[])
int fexecve (int __fd, char *const __argv[], char *const __envp[])
函数的第一个参数用来指定可执行的程序的地址。结尾为字母 p 的,接受可执行程序的文件名,操作系统会在 PATH 中去搜索该可执行文件,但如果文件名中包含 / 则将其视为路径,不再去 PATH 中搜索,而是直接访问该路径对应的文件。其他不以 p 结尾的函数要求传入可执行程序的文件路径,可以是绝对路径,也可以是相对路径。最后一个是传入可执行程序的 fd。
运行程序的时候,需要提供参数,在 C/C++ 中我们采用如下方式定义主函数(第三个参数可能不常见,但是确实是可以有的),使用 exec 执行一个程序的时候,也需要为其提供这些信息。
int main(int argc, char* argv[], char* env[]){
}
exec 系列函数除第一个参数外,都是用来指定这些信息的,只是形式不同。含有 l 字母的,表示程序的参数需要使用参数列表的形式传入,l 表示 list,下面是个例子,我调用了 ls 程序,来显示 /bin 目录下的所有文件。
execlp("ls", "ls", "/bin", nullptr);
有两点需要注意,argv 中第一个参数是程序的名称,因为参数数量不定,为标识参数的结束,最后需加一个空指针。
函数名中含有 v 的,参数需要使用字符串列表来传入,v 表示 vector。就像 main 函数的 argv 那样,注意 argv 中的最后一个元素是空指针。
如果不传递环境变量,程序在启动的时候就默认使用系统的环境变量,含有字母 e 的,可以指定环境变量。在程序中使用环境变量,可以用外部定义的 environ 变量,或者使用 main 函数的第三个参数来接收环境变量。
extern char **environ;
int main(){
for(char p=environ; *p != nullptr; p++)
printf("%s\n", *p);
}
}
// 或者
int main(int argc, char* argv[], char* env[]){
char **p = env;
while(p != nullptr){
printf("%s\n", *p);
p++;
}
}
system
system 用来执行一段命令,比如:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[]){
system("ls /bin");
printf("end");
}
system 创建了一个子进程,在子进程中执行命令,执行完成后,父进程接着执行。system 并没有去解释命令,而是把命令交给 sh 去执行:
execl("/bin/sh", "sh", "-c", command, (char *) NULL);
操作环境变量
可以操作当前进程中的环境变量,但是这些修改不会影响其他进程。
setenv("name","wangyu", 1);
printf("name: %s\n", getenv("name"));
char str[] = "email=wangyu_it@yeah.net";
putenv(str);
printf("email: %s\n", getenv("email"));
unsetenv("name");
unsetenv("email");
setjmp 和 longjmp
TODO
进程凭证
实际用户 ID 和实际组 ID
确定了进程所属的用户和组
有效用户 ID 和有效组 ID
进程组、会话、作业控制
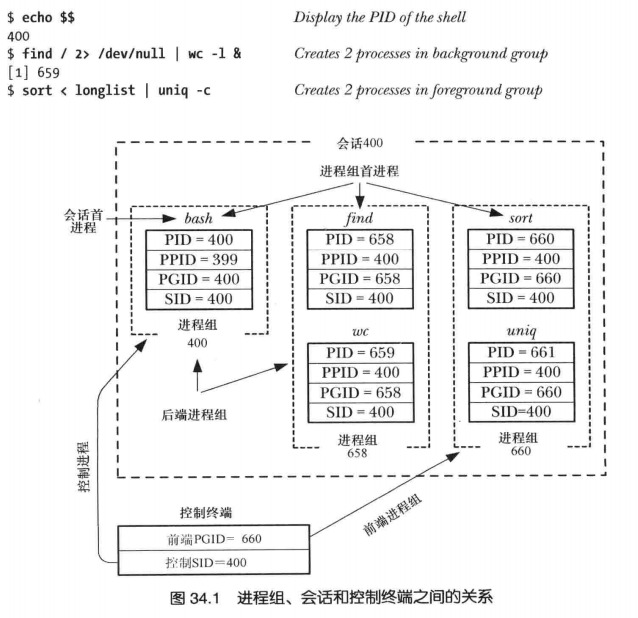
一个会话就是一个终端,会话首进程通常是终端程序,如 bash。在终端中,用户键入命令会创建新的进程,每一个命令构成一个进程组。有的命令会创建多个进程,比如使用管道连接的多个进程,这些进程处于同一个进程组。 会话包含多个进程组,进程组包含多个进程。
进程组
在特定的进程组中父进程能够等待任意的子进程,信号能够被发送到进程组中的所有进程。子进程会继承其父进程的进程组 ID。
SIGHUP 信号
当终端关闭的时候,内核会发送 SIGHUP 信号给该会话中的控制进程。还会发送一个 SIGCONT 信号,保证之前停止的进程能够重新运行。控制进程往往是 shell 程序,shell 会向它创建的其他进程组发送 SIGHUP 信号,可能还有 SIGCONT 信号。
SIGHUP 信号的默认处理方式是终止进程。
nohup 的工作原理
nohub 的源代码可以在此处看到。它先做了一些重定向,比如把标注错误输出重定向到文件。最最关键的原理性代码就下面几行:
signal(SIGHUP, SIG_IGN);
char **cmd = argv + optind;
execvp (*cmd, cmd);
先调用 signal 忽略 SIGHUP 信号,然后执行用户想要执行的命令。如此一来,进程就替换成用户命令指定的程序了。在执行 exec 之后,代码段已经被替换了,用户自定义的信号处理函数也就无处找寻了,因此用户自定义信号也就都被重置为默认了。但是在父进程中设置为 SIG_IGN 和 SIG_DFL 的信号,在子进程中依然维持原状,这就是为什么 execvp 后能够忽略 SIGHUP 信号的原因。
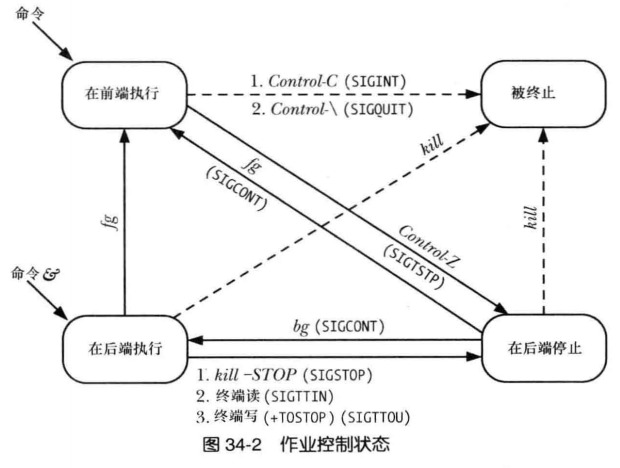
作业控制
# 在后台运行
$ sleep 100 &
# 查看当前作业
$ jobs
[1]+ Running sleep 100 & # 方括号中为作业编号
# 在前台运行 job 1,%1 表示 job 1
$ fg %1
sleep 100 # 会打印出命令
# 停止运行
$ Ctrl+Z
[1]+ Stopped sleep 100 # job 1 已经停止
$ jobs
[1]+ Stopped sleep 100 # 在后台处于停止状态
# 在后台运行 job 1
$ bg %1
[1]+ sleep 1000 &
# 在后台停止
$ kill -STOP %1 # %1 表示 job 1
下图总结了作业控制中常用的命令:
守护进程
守护进程具有如下特征:
- 生命周期很长,通常一个守护进程会在系统启动时被创建,一直运行到系统被关闭。
- 在后台运行,且没有控制终端。